Just watched Tulsa beat Fresno State in the Liberty Bowl.
Disappointing play by play - seems only fair that if we sponsor the game they mention our identity services framework more often. Maybe something along the lines of 'Man, he lost his privacy on that hit - could have used ID-WSF' or 'I don't think he would have given his consent to being thrown around like that'.
I tried to think of a more 'convergent' name - 'Meta Bowl' sounds too medical, 'URI Bowl' sounds like the Russian Mob bought the game, a 'WS-* Star Bowl' would require an indoor stadium (closed to external influences).
Maybe next year it'll simply be the 'Identity Bowl'. We could get a bunch of no-name players, opaque face masks, use encrypted URIs for uniform numbers. Advertisers would line up.
Saturday, December 31, 2005
Tuesday, December 20, 2005
RSA Security blamed for failure of many federated identity projects
In an article discussing the challenges involved in federated identity projects is the following classic from copy-editor Hell:
Too often, federation projects suffer from poor motivation/co-ordination with business partners. This may be because the complexity of the options available has been underestimated and is usually RSA Security ......As an ex-Entrust employee, I can't help but take a measure of enjoyment from this typo.
Saturday, December 17, 2005
Geographic persona URIs?
Wired has an article on the possibility of Berlin being awarded a top level domain.
The line that jumped out at me is
Nevertheless, it does suggest the possibility of personalization for such URIs beyond a user being merely able to pick their identifier in some domain.
The line that jumped out at me is
Berlin's businesses and citizens will flock to the domain because millions of people regard the hip European city as a part of their identitiesI suspect that Wired is referring to the potential of Berlin's citizenry liking the idea of a ".berlin" based email address rather than a URI identity (ala OpenID, LID etc) in the new domain.
Nevertheless, it does suggest the possibility of personalization for such URIs beyond a user being merely able to pick their identifier in some domain.
Thursday, December 15, 2005
Newswire: Liberty Alliance Changes Name
The Liberty Alliance management board has voted unanimously in favour of changing its name to the "Liberty URI Alliance".
In a prepared announcement, Liberty Alliance Prime Minister I.P. Roperty stated 'URIs have garnered significant popular enthusiasm in the industry lately. Quite simply, they are hot and we wanted to make clear that the Alliance is completely in favour of them. They are just super. Fantastic things! I fully expect to like them even more when somebody explains them to me.'
Roperty explained further 'The new name simply reflects the emphasis and priority we have always given URIs. In fact we use them all the time. For instance, Liberty's homepage has a URL and that's kind of like a URI right? I myself am considering having my name legally changed to "SAMLart". Or maybe "http://" - I haven't decided yet. Maybe they could be different personas - those are hot too'.
In a prepared announcement, Liberty Alliance Prime Minister I.P. Roperty stated 'URIs have garnered significant popular enthusiasm in the industry lately. Quite simply, they are hot and we wanted to make clear that the Alliance is completely in favour of them. They are just super. Fantastic things! I fully expect to like them even more when somebody explains them to me.'
Roperty explained further 'The new name simply reflects the emphasis and priority we have always given URIs. In fact we use them all the time. For instance, Liberty's homepage has a URL and that's kind of like a URI right? I myself am considering having my name legally changed to "SAMLart". Or maybe "http://" - I haven't decided yet. Maybe they could be different personas - those are hot too'.
Wednesday, December 14, 2005
Is it theft when identity is given away?
BugMeNot is a database of (freely provided) account names and passwords for many sites that require registration. Instead of creating an account, you ask BugMeNot for an existing account and password that will (hopefully) work there. BugMeNot looks through its previously created accounts and returns a pairing for you to use. There is even an Firefox extension to streamline the database query and form fill.
Anonymity through shared credentials.
The FAQ warns that only 'fake' (e.g. some disposable account I might create to read some online whitepaper) accounts should be registered. Nevertheless, people do appear to be registering 'real' (i.e. those for which they receive customized service) accounts.
As an example, using the BugMeNot extension, I was able (after many failed attempts) to access the (non-paid) Last.fm account of somebody named "Zudo***" and view their profile page. I know this was a real account (and not some aggregate reflection of all previous BugMeNot users who had been given this account name and password) because I was able to view which songs they had been listening to over the last week, so they must have installed the Last.fm plug-in into their music player.
Message to Zudo*** - Devo?
Anonymity through shared credentials.
The FAQ warns that only 'fake' (e.g. some disposable account I might create to read some online whitepaper) accounts should be registered. Nevertheless, people do appear to be registering 'real' (i.e. those for which they receive customized service) accounts.
As an example, using the BugMeNot extension, I was able (after many failed attempts) to access the (non-paid) Last.fm account of somebody named "Zudo***" and view their profile page. I know this was a real account (and not some aggregate reflection of all previous BugMeNot users who had been given this account name and password) because I was able to view which songs they had been listening to over the last week, so they must have installed the Last.fm plug-in into their music player.
Message to Zudo*** - Devo?
Tuesday, December 13, 2005
From the mind of a child
I was trying to explain what I do to my 6 year old son.
I presented a scenario of him playing a game at one site and then his high score being made available at some other site he travelled to.
After a pause he said 'So you help them connect?'.
'Exactly' I replied.
'But then what happens when you are sick. Do they just not connect on that day?'
I presented a scenario of him playing a game at one site and then his high score being made available at some other site he travelled to.
After a pause he said 'So you help them connect?'.
'Exactly' I replied.
'But then what happens when you are sick. Do they just not connect on that day?'
Federated log-in & email validation
While playing around with an OpenID identity I received from Videntity, I saw an interesting artifact of the federated log-in mechanism.
At LiveJournal, I opted to sign in with my Videntity Open ID instead of using my local account. Everything worked great, I was redirected to Videntity, there I logged in, and was then redirected back to LiveJournal as my OpenID identity.
However, when I clicked on 'Manage My Account' at LiveJournal, I saw the following

Because my account at LiveJournal was virtual, there was no email that would have been validated through the normal registration process. When I clicked on the 'Not Validated' string, I saw this
 LiveJournal didn't have an email for me so it tried to create one.
LiveJournal didn't have an email for me so it tried to create one.
This is of course in no way specific to OpenID but just reflects how LiveJournal's account management mechanisms assumed an old-style account in which I would have supplied an email at registration.
If I had instead supplied my email to Videntity, then (assuming I authorized its release) it could have been passed to LiveJournal and there would have been a validated email for me (albeit validated by Videntity) for LiveJournal to display.
At LiveJournal, I opted to sign in with my Videntity Open ID instead of using my local account. Everything worked great, I was redirected to Videntity, there I logged in, and was then redirected back to LiveJournal as my OpenID identity.
However, when I clicked on 'Manage My Account' at LiveJournal, I saw the following

Because my account at LiveJournal was virtual, there was no email that would have been validated through the normal registration process. When I clicked on the 'Not Validated' string, I saw this
 LiveJournal didn't have an email for me so it tried to create one.
LiveJournal didn't have an email for me so it tried to create one. This is of course in no way specific to OpenID but just reflects how LiveJournal's account management mechanisms assumed an old-style account in which I would have supplied an email at registration.
If I had instead supplied my email to Videntity, then (assuming I authorized its release) it could have been passed to LiveJournal and there would have been a validated email for me (albeit validated by Videntity) for LiveJournal to display.
ISSO & Authentication Context
Looking at the i-names SSO (ISSO) spec being defined at XDI.org, they account for some minimum password strengths by which users MUST authenticate to their i-Broker (within the XDI.org community)
To help prevent dictionary attacks, XDI.ORG MUST specify a minimum password strength required of all ISSO accounts in the XDI.ORG network.
As they use SAML 2.0 as the protocol by which the Website requests an authentication and by which the i-Broker responds, it seems strange that they don't refer to SAML 2.0's Authentication Context as the mechanism for defining such minimum authentication requirements.
To help prevent dictionary attacks, XDI.ORG MUST specify a minimum password strength required of all ISSO accounts in the XDI.ORG network.
As they use SAML 2.0 as the protocol by which the Website requests an authentication and by which the i-Broker responds, it seems strange that they don't refer to SAML 2.0's Authentication Context as the mechanism for defining such minimum authentication requirements.
Friday, December 09, 2005
Planet Identity GreaseMonkey Script
I don't like to read my own blog entries at Planet Identity so I created the following GreaseMonkey script to remove my posts.
// ==UserScript==
// @name Ignore Planet Identity Users
// @namespace http://www.planetidentity.org
// @description deletes my blogs
// @include http://www.planetidentity.org/*
// ==/UserScript==
ignorelist = new Array("Paul Madsen", "Other author");
var allDivs, thisDiv;
allDivs = document.evaluate(
'//div[@class=\"entry\"]',
document,
null,
XPathResult.UNORDERED_NODE_SNAPSHOT_TYPE,
null);
for (var i = 0; i <>
thisDiv = allDivs.snapshotItem(i);
for(j = 0; j <>
if(thisDiv.childNodes[1].childNodes[0].innerHTML == ignorelist[j]) {
thisDiv.parentNode.removeChild(thisDiv);
}
}
}
Others could use it "out of the box" or adapt as preferred by modifying the ignore list array above.
// ==UserScript==
// @name Ignore Planet Identity Users
// @namespace http://www.planetidentity.org
// @description deletes my blogs
// @include http://www.planetidentity.org/*
// ==/UserScript==
ignorelist = new Array("Paul Madsen", "Other author");
var allDivs, thisDiv;
allDivs = document.evaluate(
'//div[@class=\"entry\"]',
document,
null,
XPathResult.UNORDERED_NODE_SNAPSHOT_TYPE,
null);
for (var i = 0; i <>
thisDiv = allDivs.snapshotItem(i);
for(j = 0; j <>
if(thisDiv.childNodes[1].childNodes[0].innerHTML == ignorelist[j]) {
thisDiv.parentNode.removeChild(thisDiv);
}
}
}
Others could use it "out of the box" or adapt as preferred by modifying the ignore list array above.
Thursday, December 08, 2005
Screwy GUI
To access my frequent flier account online I have a 9-digit account number and a password.
For some reason, the Aeroplan Web designers have decided to get creative with the GUI for logging in. Rather than providing a single HTML <input> element, they've divided it up into three separate input elements.
The problem is, Firefox's password manager can only recognize one of the three input fields for form fill.
 Consequently, only the last 3 get filled in automatically.
Consequently, only the last 3 get filled in automatically.
 I guess the lesson is that if a request for identity isn't properly posed then the IDP can't respond.
I guess the lesson is that if a request for identity isn't properly posed then the IDP can't respond.
For some reason, the Aeroplan Web designers have decided to get creative with the GUI for logging in. Rather than providing a single HTML <input> element, they've divided it up into three separate input elements.
The problem is, Firefox's password manager can only recognize one of the three input fields for form fill.
 Consequently, only the last 3 get filled in automatically.
Consequently, only the last 3 get filled in automatically.  I guess the lesson is that if a request for identity isn't properly posed then the IDP can't respond.
I guess the lesson is that if a request for identity isn't properly posed then the IDP can't respond.
False sense of Security
I have the following strings of characters to remember in order to access my mortgage account through the Web or phone.
- card number
- Web password
- PIN
- telephone security string
- verbal passphrase
All these for a single account. Of course I write them down. I've complained to the bank that I shouldn't have to and thereby potentially compromise my account. No change. Seems that the perception of secerity is more important than the reality.
I wish I could forget the amount of debt as easily.
- card number
- Web password
- PIN
- telephone security string
- verbal passphrase
All these for a single account. Of course I write them down. I've complained to the bank that I shouldn't have to and thereby potentially compromise my account. No change. Seems that the perception of secerity is more important than the reality.
I wish I could forget the amount of debt as easily.
Imported Authn
In Collapse, Jared Diamond describes the impact of Australia's remoteness from the rest of the world:
I guess the only thing less bulky than a SAML assertion is an X.509 cert but historically these haven't travelled well - they start to rot in their containers round about the Equator.
The economics of the above only make sense for products low in bulk, high in intrinsic value, and, importantly, which can withstand the ordeals of the trip. You ship the concentrated juice and not the fruit; the bacon and not the hogs.
with modern globalization, it is cheaper to grow oranges in Brazil and ship the resulting orange juice concentrate 8,000 miles to Australia than to buy orange juice produced from Australian citrus trees. The same is true of Canadian pork and bacon compared to their Australian equivalents.
I guess the only thing less bulky than a SAML assertion is an X.509 cert but historically these haven't travelled well - they start to rot in their containers round about the Equator.
Wednesday, December 07, 2005
Implicit federation
The fact that federated identity connects together the current archipelago of user's identity islands is sometimes presented as enabling (or at least exacerbating) identity theft. The connections are seen as amplifying the consequences of any breach, e.g. a domino effect where one after another of your accounts is compromised.
But, if federated means connected, the different accounts of many users are already implicitly federated through the passwords that they reuse to access those accounts, this percentage of users reported as high as 40% (I confess I do it for "disposeable" accounts). If one account is successfully phished and the password is stolen for that account, it's a fair bet that that user's accounts at other providers will be accessible with the same password.
In addition to making strong and different passwords more useable for the end users, federated identity makes the connections between islands explicit and thereby manageable and controlled.
But, if two currently implicity federated (through shared password) accounts are explicity federated (through SAML 2.0, ID-FF, etc) and the passwords stay the same, then the risk of the implicit federation will remain. I'm sure users would love to be prompted with a request/demand to make sure that the passwords used at the two providers were different.
But, if federated means connected, the different accounts of many users are already implicitly federated through the passwords that they reuse to access those accounts, this percentage of users reported as high as 40% (I confess I do it for "disposeable" accounts). If one account is successfully phished and the password is stolen for that account, it's a fair bet that that user's accounts at other providers will be accessible with the same password.
In addition to making strong and different passwords more useable for the end users, federated identity makes the connections between islands explicit and thereby manageable and controlled.
But, if two currently implicity federated (through shared password) accounts are explicity federated (through SAML 2.0, ID-FF, etc) and the passwords stay the same, then the risk of the implicit federation will remain. I'm sure users would love to be prompted with a request/demand to make sure that the passwords used at the two providers were different.
Tuesday, December 06, 2005
90210
After months of running in anon mode, I decided to create an account for Pandora, a streaming music service that tailors the stream based on preferred song attributes.
Problem is, you need a US zip code to create an account.

I supplied the only US zip code I knew off hand- it was accepted with no hesitation. I have to believe that there their geographic distribution of listeners would be inappropriately skewed towards Southern California.
Problem is, you need a US zip code to create an account.
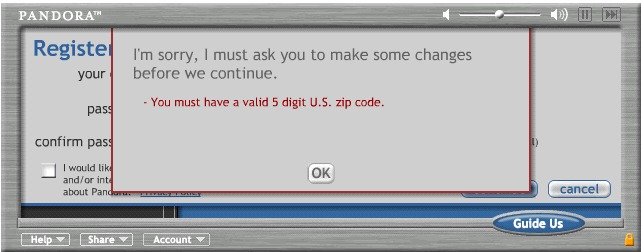
I supplied the only US zip code I knew off hand- it was accepted with no hesitation. I have to believe that there their geographic distribution of listeners would be inappropriately skewed towards Southern California.
Social Tags
One interesting (but admittedly only rudimentarily defined) aspect of Liberty's new People Service is the ability for users to tag the friends, colleagues, and family members (and any groups into which they are placed) that are members of their PS list.
Each friend or group Object can have multiple optional Tag elements, each with a ref attribute carrying a tag value (recommended to be in some established taxonomy like Flickr or Del.icio.us).
Tags are seen as an extra (to the friendly name) axis along which user's can categorize their friends and groups. As an example, if a user created two groups called 'Soccer Team' and 'Hockey Team', both groups could be tagged with 'sports' to make clear their shared relationship (as opposed to placing both in some extra hierarchal level through a 'Sports Teams' group).
Once both groups are tagged, access rights (e.g. allow any of my team-mates, irrespective of sport, to see this video) or group operations (e.g. send a party invite to all my team-mates) can be defined against the tag rather than the individual groups or individuals that have that tag.
We have much to learn here.
Each friend or group Object can have multiple optional Tag elements, each with a ref attribute carrying a tag value (recommended to be in some established taxonomy like Flickr or Del.icio.us).
Tags are seen as an extra (to the friendly name) axis along which user's can categorize their friends and groups. As an example, if a user created two groups called 'Soccer Team' and 'Hockey Team', both groups could be tagged with 'sports' to make clear their shared relationship (as opposed to placing both in some extra hierarchal level through a 'Sports Teams' group).
Once both groups are tagged, access rights (e.g. allow any of my team-mates, irrespective of sport, to see this video) or group operations (e.g. send a party invite to all my team-mates) can be defined against the tag rather than the individual groups or individuals that have that tag.
We have much to learn here.
Geolocation with no privacy implications
Petscell is a GPS-enabled cell for pets, allowing owners to track the location of Fido.
Remote programmable geo-fence capability. Yes, I'm sure the dog will stop and come home when it gets a call.
Fortunately my children have gerbils - the phone's weight would crush them and I always know where the things are.
Remote programmable geo-fence capability. Yes, I'm sure the dog will stop and come home when it gets a call.
Fortunately my children have gerbils - the phone's weight would crush them and I always know where the things are.
Monday, December 05, 2005
Killer Identity App
Judging by the conversations I heard after the Captain turned off the seat belt sign on a trip last week to Austin, there is a killer app just waiting to be built. It needs a slick marketing name but the jist of it is 'Hey, yeah we just landed, see you in 20 minutes, bye'.
Seems that many passengers have family, friends, colleagues who wait anxiously by their phones for just such brief but meaningful status updates.
Liberty's Identity Web Service Framework (ID-WSF) has all the necessary components to support such a system:
- People Service - defines a service by which one user can track those others with which they engage in online interactions
- Geolocation Service - defines a protocol by which the geographic coordinates of a user can be queried
- Subscription & notification - mechanism by which identity info requestors can subscribe to be notified if and when certain criteria are met
So, Frequent Flier uses a People Service to track their relationship with Friend, and then defines access rules at their cell phone provider such that Friend (referenced through the People Service) can see their geolocation. When Frequent Flier surreptiously turns their cell on immediately after touch down, the previously defined notification criteria (i.e. that Frequent Flier's location be within some distance of a major airport) triggers a message to that effect being sent to Friend.
You could even track miles flown for status. Maybe then I wouldn't need to save boarding pass stubs on the chance of my miles not being credited.
Seems that many passengers have family, friends, colleagues who wait anxiously by their phones for just such brief but meaningful status updates.
Liberty's Identity Web Service Framework (ID-WSF) has all the necessary components to support such a system:
- People Service - defines a service by which one user can track those others with which they engage in online interactions
- Geolocation Service - defines a protocol by which the geographic coordinates of a user can be queried
- Subscription & notification - mechanism by which identity info requestors can subscribe to be notified if and when certain criteria are met
So, Frequent Flier uses a People Service to track their relationship with Friend, and then defines access rules at their cell phone provider such that Friend (referenced through the People Service) can see their geolocation. When Frequent Flier surreptiously turns their cell on immediately after touch down, the previously defined notification criteria (i.e. that Frequent Flier's location be within some distance of a major airport) triggers a message to that effect being sent to Friend.
You could even track miles flown for status. Maybe then I wouldn't need to save boarding pass stubs on the chance of my miles not being credited.
Panopticon - an overlooked aspect
Stefan Brands often uses the metaphor of the pantopticon to criticise federated identity models (like one possible manifestation of the Liberty Alliance architecture) in which a user's interactions with service providers are (partially) mediated by identity providers.
Stefan and Sun's Pat Patterson had an interesting discussion on the issue a while back. I won't revisit that - it's undeniable that in the LAP model that the IDP may 'learn', the discussion is to the what (it learns) and the when (it isn't appropriate).
There is another aspect of the panopticon model that gets lost in the 'IDP surveillance' theme. Panopticon refers to a proposed model for prison architecture and process in which inmates were distributed in isolated cells about a centralized watch station. In addition to the intermittent surveillance that was enabled, the architecture ensured that inmates had no contact with each other or prison officials. The theory was that such contact would interfere with the inmates reformation.
Liberty today announced the release of another rev of its identity web services framework. This release includes support for what Liberty is calling a People Service. Bottom line, People Service is designed to allow users to manage their online relationships (e.g. friends, colleagues, and family, etc) such that the various applications that depend on a social layer (e.g. photo sharing, Find a Friend, YASN, etc) can build on a single consistent social network rather than each building their own duplicative version. A bit like a SOAP API into a FOAF repository.
The People Service is a key enabler of cross-principal web service interactions, e.g. those where the identity on whose behalf a request is sent is different than the identity that owns the identity resource in question (some site querying my wife's online calendar but indicating that the request is being sent on my behalf.) A key bit of this release of WSF is defining how the multiple identities in such a scenario are expressed in the SOAP Header.
The (admittedly limited) irony is that the ID-WSF People Service enables just the sort of interactions between individuals that the panoptical model for prison (and hospital) architecture was designed to prevent. No analogy is perfect it seems.
The PS spec is here and there is a whitepaper as well.
Stefan and Sun's Pat Patterson had an interesting discussion on the issue a while back. I won't revisit that - it's undeniable that in the LAP model that the IDP may 'learn', the discussion is to the what (it learns) and the when (it isn't appropriate).
There is another aspect of the panopticon model that gets lost in the 'IDP surveillance' theme. Panopticon refers to a proposed model for prison architecture and process in which inmates were distributed in isolated cells about a centralized watch station. In addition to the intermittent surveillance that was enabled, the architecture ensured that inmates had no contact with each other or prison officials. The theory was that such contact would interfere with the inmates reformation.
solitude is in its nature subservient to the purpose of reformation
Liberty today announced the release of another rev of its identity web services framework. This release includes support for what Liberty is calling a People Service. Bottom line, People Service is designed to allow users to manage their online relationships (e.g. friends, colleagues, and family, etc) such that the various applications that depend on a social layer (e.g. photo sharing, Find a Friend, YASN, etc) can build on a single consistent social network rather than each building their own duplicative version. A bit like a SOAP API into a FOAF repository.
The People Service is a key enabler of cross-principal web service interactions, e.g. those where the identity on whose behalf a request is sent is different than the identity that owns the identity resource in question (some site querying my wife's online calendar but indicating that the request is being sent on my behalf.) A key bit of this release of WSF is defining how the multiple identities in such a scenario are expressed in the SOAP Header.
The (admittedly limited) irony is that the ID-WSF People Service enables just the sort of interactions between individuals that the panoptical model for prison (and hospital) architecture was designed to prevent. No analogy is perfect it seems.
The PS spec is here and there is a whitepaper as well.
InteracOnline

A number of Canadian banks have created a federated payment system called InteracOnline. Consumers can pay direct from their banking account, comparable to debit cards versus credit cards at the cash.
They don't use the term but the claimed benefits for the consumer read right out of federated identity white papers:
- Privacy: you do not need to provide any financial details, card numbers or login information to the online merchant.
- Ease of use: because the payment is conducted through web banking, you don’t need to worry about creating any new passwords or accounts.
- Security: the payment is completed through the Financial Institution you know and trust.
- Spending Control: The Interac Online service helps you better manage your finances – you can’t spend more than what you have in your bank account!
Despite the currently small number, there seems quite the mix of participating merchants. Professional curiosity as to implementation, UI design etc will almost certainly require me to conduct further research at one or two of these sites (most likely chosen at random).
Thursday, November 24, 2005
Social Navigation
Supposedly, it's easier to just ask someone nearby where you are rather or how to get someplace than using mobile navigation applications - at least until the phone interfaces make this less cumbersome.
Whoever believes this has never asked a random passerby how to get to Ueno Park from Shinjuku in Tokyo. 'Sumimasen, Ueno doko desu ka?' only gets you so far.
Whoever believes this has never asked a random passerby how to get to Ueno Park from Shinjuku in Tokyo. 'Sumimasen, Ueno doko desu ka?' only gets you so far.
Wednesday, November 23, 2005
Ummmmm Bacon
Andre Durand conjectures that the network is collapsing (in the sense that nodes, be they devices or people, are more easily connected than in the past). With the help of his mathematician father, he explores the rate of collapse, e.g. from year to year how much closer are the nodes. Interesting stuff.
As a starting point, they use what they call 'Kevin Bacon's 6 Degrees Theory'. Problem is, I don't think there is such a theory - this expression conflates two different ideas of small-world research.
The first is the well-known '6 degrees of separation' theory - the idea that anyone on the Earth can be connected to any other through a chain of at most 5 acquaitances. The second aspect is a game called 'Six Degrees of Kevin Bacon' in which Hollywood actors are labelled by their 'distance' from Kevin Bacon, this determined by how many links there are in the chain of co-actors between them and Bacon. So, different actors are said to have different 'Bacon numbers' (just as mathematicians can be labelled by their Erdos number)
But, as far as I know, there has never been a conjecture that the number 6 is in any way special for the Bacon number. A variety of actors will have this for a Bacon number, but many others will have Bacon numbers of 5 and 7.
It's meaningful to explore either the possibility that '6 degrees of separation' is becoming '5 degress of separation' (likely but by no means certain) or the possibility that a given actor's Bacon number decreases over time (it can't get larger) - but seems to me that Andre and his father are trying to combine the two.
Maybe we should define a Cameron Number, e.g. how distant people are from Microsoft's Kim Cameron - this distance defined with respect to blog roll membership (among other possible criteria like shared conference attendance). I don't personally know Kim but nonetheless have a Cameron Number of '2' (thank you Pat Patterson).
As a starting point, they use what they call 'Kevin Bacon's 6 Degrees Theory'. Problem is, I don't think there is such a theory - this expression conflates two different ideas of small-world research.
The first is the well-known '6 degrees of separation' theory - the idea that anyone on the Earth can be connected to any other through a chain of at most 5 acquaitances. The second aspect is a game called 'Six Degrees of Kevin Bacon' in which Hollywood actors are labelled by their 'distance' from Kevin Bacon, this determined by how many links there are in the chain of co-actors between them and Bacon. So, different actors are said to have different 'Bacon numbers' (just as mathematicians can be labelled by their Erdos number)
But, as far as I know, there has never been a conjecture that the number 6 is in any way special for the Bacon number. A variety of actors will have this for a Bacon number, but many others will have Bacon numbers of 5 and 7.
It's meaningful to explore either the possibility that '6 degrees of separation' is becoming '5 degress of separation' (likely but by no means certain) or the possibility that a given actor's Bacon number decreases over time (it can't get larger) - but seems to me that Andre and his father are trying to combine the two.
Maybe we should define a Cameron Number, e.g. how distant people are from Microsoft's Kim Cameron - this distance defined with respect to blog roll membership (among other possible criteria like shared conference attendance). I don't personally know Kim but nonetheless have a Cameron Number of '2' (thank you Pat Patterson).
Tuesday, November 22, 2005
QR codes for two-factor authentication

On a recent trip to Tokyo, I was able to see some of the work of my colleagues at the Tokyo NTT Information Platform Sharing Laboratories exploring the potential of two-channel authentication systems. Such systems generally depend on various permutations of secrets shared across both a PC channel and a separate device channel. In essence, the phone serves as a second authentication factor.
Existing two-channel systems rely on either:
1) the client providing a phone number at registration time to which the service provider sends a OTP over SMS when the user logs in. When received by the user on their phone, they then enter it on the PC interface. By verifying the presented OTP, the server can be confident that the user is indeed the owner of the phone and therefore the account holder.
2) the server creating a one time phone number and presenting it to the user through the PC-channel. The user then calls this number from a phone with a previously registered number. The server, by verifying that the call came from a registered number, can be confident that the user is the account holder.
Both systems require that the user's phone number be provided to the server, which presents both privacy and scaleability (the server has to store these numbers) issues. The first relies on the security of SMS.
My colleagues are working on alternatives that:
a) don't rely on a phone number being registered/stored
b) leverage the certificates on many Japanese phones for client-auth SSL
c) authenticate the server as well
In both models above, it is the user that acts as the conduit by which the PC and phone channels are connected (this necessary for them to be correlated and authenticated). In the first, the user takes the OTP from the phone and types it into some HTML form; in the second, the user takes the presented phone number and manually dials it.
The research is exploring the potential for a technology mostly unique to the Japanese market to provide this connection/interface between the two channels. QR codes are two-dimensional bar codes into which can be embedded significantly more information. Critically, over 77% of Japanese phones have support for QR code readers. The phones' cameras can thereby serve as the conduit through which the two channels can be connected and correlated.
The prototype system has the server generate a dynamic QR code and present it to the user when authentication is required. The user uses their phone to take a picture of the code from their PC screen - the phone QR software then extracts the corresponding server address to which a mutual SSL session is established. To authenticate the server, the user sends a short text string from their PC as a nonce that the server signs and presents to the phone.
Below are pictures of 1) a user taking a picture of an on-screen QR code with their phone and 2) the phone display by which the server is authenticated.
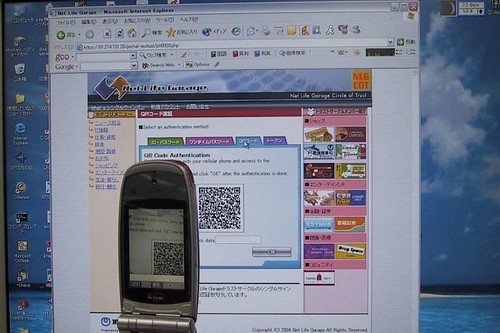
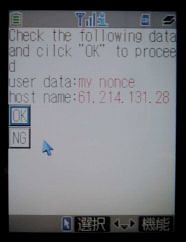
The system is attractive because it leverages a (ubiquitous) second factor that users already have and expect to use, requires no specialized client software, does away with the privacy/scaling issue of stored phone numbers, and doesn't rely on the questionable security of SMS.
As Bruce Schneier points out, such systems can't guard against MITM attacks:
An attacker using a man-in-the-middle attack is happy to have the user deal with the SMS portion of the log-in, since he can't do it himself.
Nevertheless, to say that a technology doesn't prevent one attack doesn't mean they provide no value in defending against others.
Monday, November 21, 2005
Separation of Powers
Separation of powers is the concept within democratic government in which powers are distributed amongst different government organs to prevent any one of them from abusing that power. Along with checks-and-balances (the ability and responsibility of each to monitor the activities of the others), separation of powers is intended to reduce opportunities for tyranny.
Federated identity is sometimes criticized for exacerbating the risk of identity theft through its connection of currently separate identity collections into a greater virtual whole. The argument goes something like:
'So, if I login to the identity provider, I can then access my resources at some other service provider? That sounds nice but what happens if my identity at the identity provider is stolen/phished/pharmed/hacked, can't the thief, because of the connection, immediately jump to the service provider and steal my identity there?'
The argument is based on the assumption that some rogue individual, on hacking the identity provider, can get everything they need in order to impersonate me so that they can access my multiple federated service provider accounts.
Here is the rub though. It does the hacker no good to impersonate me, they have to impersonate the identity provider. As they do not know my various service provider credentials, they have to convince the service provider that they are the identity provider asserting to my authentication status. And, the burden of authenticating one site to another site (not to a user as in phishing) is considerably more challenging for a hacker.
If a hacker is to fool a service provider into accepting a counterfeit assertion for me (and thereby assume my identity at that service provider) it needs to present two things:
1) whatever federated identifier had previously been agreed upon between the service provider and the identity provider for myself. Present a random string and the service provider will refuse access because it won't recognize it as one of its federated users. Even if the hacker were to by chance get lucky and pick a valid identifier, its only valid when presented by the corresponding identity provider. see 2) below
2) a signature over the message carrying the above identifier associated with a key trusted by that service provider. Not any key issued by Verisign will do, the service provider will certainly keep a list of 'trusted IDPs' and if the associated key is not on the list then you are not invited to the party.
If the identity provider does things "right", then it will ensure that it is very difficult for any one entity (internal or external) to steal both of the above (it will almost certainly make it difficult to steal either as well). A "good" identity provider will implement "separation of powers" to ensure that, were one of the above was stolen, the other wouldn't be.
You can fool such an IDP once, but likely not twice.
"There's an old saying in Tennessee — I know it's in Texas, probably in Tennessee — that says, fool me once, shame on — shame on you. Fool me — you can't get fooled again." —President George W. Bush, Nashville, Tenn., Sept. 17, 2002
Federated identity is sometimes criticized for exacerbating the risk of identity theft through its connection of currently separate identity collections into a greater virtual whole. The argument goes something like:
'So, if I login to the identity provider, I can then access my resources at some other service provider? That sounds nice but what happens if my identity at the identity provider is stolen/phished/pharmed/hacked, can't the thief, because of the connection, immediately jump to the service provider and steal my identity there?'
The argument is based on the assumption that some rogue individual, on hacking the identity provider, can get everything they need in order to impersonate me so that they can access my multiple federated service provider accounts.
Here is the rub though. It does the hacker no good to impersonate me, they have to impersonate the identity provider. As they do not know my various service provider credentials, they have to convince the service provider that they are the identity provider asserting to my authentication status. And, the burden of authenticating one site to another site (not to a user as in phishing) is considerably more challenging for a hacker.
If a hacker is to fool a service provider into accepting a counterfeit assertion for me (and thereby assume my identity at that service provider) it needs to present two things:
1) whatever federated identifier had previously been agreed upon between the service provider and the identity provider for myself. Present a random string and the service provider will refuse access because it won't recognize it as one of its federated users. Even if the hacker were to by chance get lucky and pick a valid identifier, its only valid when presented by the corresponding identity provider. see 2) below
2) a signature over the message carrying the above identifier associated with a key trusted by that service provider. Not any key issued by Verisign will do, the service provider will certainly keep a list of 'trusted IDPs' and if the associated key is not on the list then you are not invited to the party.
If the identity provider does things "right", then it will ensure that it is very difficult for any one entity (internal or external) to steal both of the above (it will almost certainly make it difficult to steal either as well). A "good" identity provider will implement "separation of powers" to ensure that, were one of the above was stolen, the other wouldn't be.
You can fool such an IDP once, but likely not twice.
"There's an old saying in Tennessee — I know it's in Texas, probably in Tennessee — that says, fool me once, shame on — shame on you. Fool me — you can't get fooled again." —President George W. Bush, Nashville, Tenn., Sept. 17, 2002
It's a Mad Mad World
In the Cold War, Washington advertised one policy for the use of its nuclear weapons while privately holding a very different strategy.
The visible & public policy was referred to as Assured Destruction (the 'mutual' was later added by a critic to create a more derisive acronym). AD was the idea that the only sane application of nuclear weapons was a non-application - if both sides were completely confident that they would be destoyed in any altercation they would be unwilling to strike first, and so nuclear weapons would never be used. The opposing counterforce strategy (which Qwynne Dwyer in his book War claims Washington actually held even whilst professing AD) saw such weapons providing value above and beyond their deterrent effect through their potential delivery in a controlled and constrained manner in a conventional war .
So, the "real" policy was much less restrictive in its criteria governing the 'release' of the ICBMs. While AD was based on the premise that one side's missiles would only be lanuched in retaliation to a first strike from the other side (stringent criteria) - the counterforce policy asserted that weapons could be deployed in a range of situations, e.g. in a tactical manner even as part of a convential non-nuclear altercation (relaxed criteria).
(This is the exact opposite of what I might have expected, e.g. a public bluff of aggressiveness but a more realistic and sane private plan. Of course, there were vested interests involved for which the status quo of maintaining weapon expenditure was desirable)
I wonder if the idea of different public/private policies is relevant for any policy governing release of identity information? Would a provider claim to be governed by one policy whilst actually listening to another?
If the visible policy were less stringent than the actual, the provider would receive attribute requests that would be immediately rejected - requests that would not have been sent if the advertised policy were accurate. Beyond the inefficiency, this is a privacy leak as the provider would unnecessarily learn at which requestor sites the principal had been visiting. If the advertised policy were more stringent, then the requestor might not even send requests that would be approved had they been - doesn't seem much risk (or sense) in this.
The visible & public policy was referred to as Assured Destruction (the 'mutual' was later added by a critic to create a more derisive acronym). AD was the idea that the only sane application of nuclear weapons was a non-application - if both sides were completely confident that they would be destoyed in any altercation they would be unwilling to strike first, and so nuclear weapons would never be used. The opposing counterforce strategy (which Qwynne Dwyer in his book War claims Washington actually held even whilst professing AD) saw such weapons providing value above and beyond their deterrent effect through their potential delivery in a controlled and constrained manner in a conventional war .
So, the "real" policy was much less restrictive in its criteria governing the 'release' of the ICBMs. While AD was based on the premise that one side's missiles would only be lanuched in retaliation to a first strike from the other side (stringent criteria) - the counterforce policy asserted that weapons could be deployed in a range of situations, e.g. in a tactical manner even as part of a convential non-nuclear altercation (relaxed criteria).
(This is the exact opposite of what I might have expected, e.g. a public bluff of aggressiveness but a more realistic and sane private plan. Of course, there were vested interests involved for which the status quo of maintaining weapon expenditure was desirable)
I wonder if the idea of different public/private policies is relevant for any policy governing release of identity information? Would a provider claim to be governed by one policy whilst actually listening to another?
If the visible policy were less stringent than the actual, the provider would receive attribute requests that would be immediately rejected - requests that would not have been sent if the advertised policy were accurate. Beyond the inefficiency, this is a privacy leak as the provider would unnecessarily learn at which requestor sites the principal had been visiting. If the advertised policy were more stringent, then the requestor might not even send requests that would be approved had they been - doesn't seem much risk (or sense) in this.
Friday, November 18, 2005
Bidirectional PII leakage
Motivated by a spate of fiascos and consequent legislation, enterprises are currently focussed on ensuring that any privacy sensitive data they may hold about individuals doesn't leak out.
Given the risks of damage to reputation and liability associated with storage of such data, how long is it before enterprises worry just as much about not allowing PII to leak in?
Ben Laurie suggests that one tenet of privacy-respecting identity management is minimalism, i.e. that only that identity information required for a particular application be shared and no more. He describes it as a principal for the protection of the individual - which it is of course.
But, it's also protection for the data requestor/recipient. Unless it has an immediate and (business)justifiable need for some piece if identity information, why ask for it, or even accept it if not requested but nonetheless offered? Or store it past any usage? Better let some identity provider, presumably with a business model and corresponding security technology and processes take the burden and risk.
Just remember to log that you didn't accept it.
Given the risks of damage to reputation and liability associated with storage of such data, how long is it before enterprises worry just as much about not allowing PII to leak in?
Ben Laurie suggests that one tenet of privacy-respecting identity management is minimalism, i.e. that only that identity information required for a particular application be shared and no more. He describes it as a principal for the protection of the individual - which it is of course.
But, it's also protection for the data requestor/recipient. Unless it has an immediate and (business)justifiable need for some piece if identity information, why ask for it, or even accept it if not requested but nonetheless offered? Or store it past any usage? Better let some identity provider, presumably with a business model and corresponding security technology and processes take the burden and risk.
Just remember to log that you didn't accept it.
SP Collusion
Dictionary.com defines 'collude' as
'To act together secretly to achieve a fraudulent, illegal, or deceitful purpose; conspire'.
In the context of identity management, the term is typically used to refer to multiple providers communicating together about some principal without that principal's consent.
If each provider stores some aspect of a given principal's digital identity - collusion between them is made possible if the nature of such identity information allows them to infer that it is the same individual with which they both have accounts.
Federated identity management, if done improperly, can enable collusion by simplifying the correlation burden for the rogue providers. This because, valid (e.g. based on informed consent) connections between the two providers and some other third provider can provide to the rogue providers the necessary correlation keys.
Federated single sign-on (SSO) can be used to explore the dangers. In SSO, a user authenticates to an IDP, and then the IDP creates claims to that effect for use at other SPs. Correlation and collusion is enabled if the claims are not created carefully. If the same user presents two different claims to two different SPs, the SPs might be able to correlate the claims as referring to the same principal through any of the following mechanisms:
A common identifier in both claims, e.g. if an email address or SSN is used to identity the subject for which the claim was generated. SAML 2 and Liberty address this by defining mechanisms by which identifiers unique to each IDP-SP pairing are established and used.
sufficiently identifying attributes, e.g. if both claims describe me as male, 41, working on identity management, living in Canada, tired father of 3, then the SPs would be able to infer that their different local acocunts referred to the same user, me.
small-community IDP, e.g. if both claims are issued by an IDP known to only issue claims for a small community of end users, then the SPs can narrow down their focus. If the IDP is associated with a single principal then its trivial.
temporally, e.g. if the two SPs somehow knew that the nature of some other application required real-time data from both of them, then perhaps they could use the timing of the requests to correlate. For instance, one SP is a calendar service, another a shipping service. If both SPs received a request for one of their user's data within some window of time from a home grocers site, then the two SPs could infer that their two users might be the same. If it happened again it would be confirmed.
keying material, e.g. if the keys used to ensure HOK subject binding were to be reused for the two SPs, then they could correlate based on that.
I'm sure there are others.
'To act together secretly to achieve a fraudulent, illegal, or deceitful purpose; conspire'.
In the context of identity management, the term is typically used to refer to multiple providers communicating together about some principal without that principal's consent.
If each provider stores some aspect of a given principal's digital identity - collusion between them is made possible if the nature of such identity information allows them to infer that it is the same individual with which they both have accounts.
Federated identity management, if done improperly, can enable collusion by simplifying the correlation burden for the rogue providers. This because, valid (e.g. based on informed consent) connections between the two providers and some other third provider can provide to the rogue providers the necessary correlation keys.
Federated single sign-on (SSO) can be used to explore the dangers. In SSO, a user authenticates to an IDP, and then the IDP creates claims to that effect for use at other SPs. Correlation and collusion is enabled if the claims are not created carefully. If the same user presents two different claims to two different SPs, the SPs might be able to correlate the claims as referring to the same principal through any of the following mechanisms:
I'm sure there are others.
Thursday, November 17, 2005
SSSO - Social Single Sign On
There is nothing social in default SSO. There is a single user and he/she, based on an authentication performed at some identity provider, is granted appropriate access for their own resources at some service provider. There would seem to be some unexplored social (i.e. more than a single user involved) aspects of SSO.
For instance, a user may be SSOing in to access resources belonging to another user. If I define the permissions at some online photo site such that certain friends can see my recent photos; if and when those friends log-in to that photo site they will be granted those privileges. If they log-in with an account local to the photo site then its very straightforward for me to define privileges against the corresponding identifier and for the site itself to enforce them. This is how sharing currently works at such sites.
However, if they don't have such an account nor desire to create one, they will want to access my photos based on an authentication performed elsewhere, e.g. SSO in to the photo site. The challenge now becomes how the photo site gets an identifier for the friend to which the privileges can be assigned and how users can track and manage the social relationships relevant to their online interactions. The Liberty Alliance People Service is designed to facilitate this.
Another social angle comes from the fact that, in many situations, the nature of the credential by which a user authenticates to an IDP is such that the IDP can't unambiguously identify them as individuals. For instance, when I access the Net from my home PC, my ISP knows only that I am one of the family members with access to that PC. Based on that shared credential I should be able to SSO to some SP and be granted permissions appropriate to mmy family, but not to any particular member. So, I might be able to see the family's calendar but not my personal one (at least not until I re-authenticated with a credential that did allow the IDP to unambiguously identify me and make an assertion to this effect to the SP).
For instance, a user may be SSOing in to access resources belonging to another user. If I define the permissions at some online photo site such that certain friends can see my recent photos; if and when those friends log-in to that photo site they will be granted those privileges. If they log-in with an account local to the photo site then its very straightforward for me to define privileges against the corresponding identifier and for the site itself to enforce them. This is how sharing currently works at such sites.
However, if they don't have such an account nor desire to create one, they will want to access my photos based on an authentication performed elsewhere, e.g. SSO in to the photo site. The challenge now becomes how the photo site gets an identifier for the friend to which the privileges can be assigned and how users can track and manage the social relationships relevant to their online interactions. The Liberty Alliance People Service is designed to facilitate this.
Another social angle comes from the fact that, in many situations, the nature of the credential by which a user authenticates to an IDP is such that the IDP can't unambiguously identify them as individuals. For instance, when I access the Net from my home PC, my ISP knows only that I am one of the family members with access to that PC. Based on that shared credential I should be able to SSO to some SP and be granted permissions appropriate to mmy family, but not to any particular member. So, I might be able to see the family's calendar but not my personal one (at least not until I re-authenticated with a credential that did allow the IDP to unambiguously identify me and make an assertion to this effect to the SP).
Wednesday, November 16, 2005
False claims?
Will an identity system allow me to lie?
I (and I expect most others) often provide false data to sites asking me for personal data. I'm more likely to do so if the site is asking me for specific identity information as opposed to some range. For instance, if the site asks for my birth date (or even age) it's very unlikely that I'll give the actual date (unless it will eventually serve as some credential). If instead, the site provides me a set of ranges of ages from which I can select I am far more inclined to be truthful.
Now, if an SP were to ask an IDP of mine for my age rather than me directly, what happens if the SP and request are such that I don't want the IDP to provide the real value. Does the IDP provide a value from a persona I've set up just for such requests? What is the meaning of such an assertion if there is another persona with my real age, i.e. is the IDP asserting to the truth of its claim or merely to the fact that its asserting a value previously supplied by me?
Seems to me that the problem with the current status quo of sites asking for my age is that there is no 'fall-back' option, e.g. if I want to proceed with setting up the account or purchasing whatever, the HTML form requires me to provide a value for the field. There is no negotiation possible, no leeway in the site's identity demands and consequently I respond with the only option that satisfies both this demand and my desire for privacy - I lie.
In the brave new world of identity, perhaps there is no need to lie. If an SP asks my IDP for my age, the IDP might respond with 'Why do you need it?', to which the SP would say 'Demographic study', so that the IDP would finish with 'Well then his age range of '35-45' will be sufficient'. Because there needn't be a binary yes/no for release of identity data, but a negotiated middle-ground, its more likely that both the SPs and mine can be satisfied.
I (and I expect most others) often provide false data to sites asking me for personal data. I'm more likely to do so if the site is asking me for specific identity information as opposed to some range. For instance, if the site asks for my birth date (or even age) it's very unlikely that I'll give the actual date (unless it will eventually serve as some credential). If instead, the site provides me a set of ranges of ages from which I can select I am far more inclined to be truthful.
Now, if an SP were to ask an IDP of mine for my age rather than me directly, what happens if the SP and request are such that I don't want the IDP to provide the real value. Does the IDP provide a value from a persona I've set up just for such requests? What is the meaning of such an assertion if there is another persona with my real age, i.e. is the IDP asserting to the truth of its claim or merely to the fact that its asserting a value previously supplied by me?
Seems to me that the problem with the current status quo of sites asking for my age is that there is no 'fall-back' option, e.g. if I want to proceed with setting up the account or purchasing whatever, the HTML form requires me to provide a value for the field. There is no negotiation possible, no leeway in the site's identity demands and consequently I respond with the only option that satisfies both this demand and my desire for privacy - I lie.
In the brave new world of identity, perhaps there is no need to lie. If an SP asks my IDP for my age, the IDP might respond with 'Why do you need it?', to which the SP would say 'Demographic study', so that the IDP would finish with 'Well then his age range of '35-45' will be sufficient'. Because there needn't be a binary yes/no for release of identity data, but a negotiated middle-ground, its more likely that both the SPs and mine can be satisfied.
Saturday, October 22, 2005
Airport Perimeter Security
Leaving Singapore the other day at Changi Airport, I saw different model for security than what seems to be default of a single security checkpoint (e.g. X-ray machine and wand-waving, body-frisking attendants) for all gates.
At Changi, you don't go through security until you reach your gate, each gate has its own security checkpoint. The advantages of centralizing security seem clear - so I started thinking as to what might the advantages of this distributed model.
Theoretically possible would be security customized to the destination, e.g. for flights to political hotspots, full rigour (e.g. laptops get sniffed, every bag gets checked, random body searches, etc) for other destinations, less intrusive security. Travel to such 'safer' destinations wouldn't pay the price of security appropriate to riskier destinations. I don't know if they actually do this.
I saw a specific example of another advantage. As we moved through security at the gate for my flight to Tokyo, the traveller just in front of me was informed by the personnel that he was at the wrong gate. This sort of application-layer check isn't possible with the centralized gatekeeper security model - the gatekeeper doesn't have the application details and so can't apply security based on them.
At Changi, you don't go through security until you reach your gate, each gate has its own security checkpoint. The advantages of centralizing security seem clear - so I started thinking as to what might the advantages of this distributed model.
Theoretically possible would be security customized to the destination, e.g. for flights to political hotspots, full rigour (e.g. laptops get sniffed, every bag gets checked, random body searches, etc) for other destinations, less intrusive security. Travel to such 'safer' destinations wouldn't pay the price of security appropriate to riskier destinations. I don't know if they actually do this.
I saw a specific example of another advantage. As we moved through security at the gate for my flight to Tokyo, the traveller just in front of me was informed by the personnel that he was at the wrong gate. This sort of application-layer check isn't possible with the centralized gatekeeper security model - the gatekeeper doesn't have the application details and so can't apply security based on them.
Wednesday, October 12, 2005
SPeciation
In evolutionary biology, speciation refers to the process by which different species emerge out of some common ancestor. Species are defined by the ability of their members to interbreed successfully (this measured by creating viable offspring) so the emergence of two species from a single common stock implies that some genetic separation be established where there was none before.
By this criteria, SAML 1.1, Liberty ID-FF 1.2, and Shibboleth were not different species as the three of them participated (I hesitate to use a more common phrase for such co-operation) in a furious orgy of successful interbreeding to create SAML 2.0.
p.s. Evolutionary science has another term that those more cynical than I might apply to other creatures participating in the current Malthusian struggle to pass on their identity management genes.
By this criteria, SAML 1.1, Liberty ID-FF 1.2, and Shibboleth were not different species as the three of them participated (I hesitate to use a more common phrase for such co-operation) in a furious orgy of successful interbreeding to create SAML 2.0.
p.s. Evolutionary science has another term that those more cynical than I might apply to other creatures participating in the current Malthusian struggle to pass on their identity management genes.
Tuesday, October 04, 2005
Ning Identity
Ning describes itself as a playground for creating social apps. It provides a common layer of registration, authentication, tags, feeds etc onto which people can build a variety of socially-aware apps (e.g. Zagat-like restaurant reviews, Flickr-like photo sharing, etc). To enable the creation of new apps, developers can clone existing applications, and then tinker with the PHP to tailor as required. Much like 'View Source' for HTML/Javascript.
The SSO across all these apps is interesting. As its based on a 'global' identifier, the implication is that Ning would be able to correlate any one user's actions/identity across all these purportedly different applications.
It appears that Ning acknowledges this as a concern because the FAQ has the following
The SSO across all these apps is interesting. As its based on a 'global' identifier, the implication is that Ning would be able to correlate any one user's actions/identity across all these purportedly different applications.
It appears that Ning acknowledges this as a concern because the FAQ has the following
I want to use different email addresses and identities for different apps. Can I do that without creating two accounts?
Not at the moment. For now, you probably should just go ahead and use one of the many free email services that are happy to give you as many free email addresses as you want.
Thursday, September 29, 2005
Intrinsic analysis vs social smarts
Last.fm and Pandora take two different approaches to the problem of helping people find new music that they are likely to enjoy.
Pandora asks you to provide the name of an artist or song as a starting point. Then, based on its prior analysis of the song or artist, it recommends 'similar' songs that meet the search criteria. Amazingly, the analysis of each song is perfromed by humans
The Pandora player streams these relevant songs and allows you to customize with your likes/dislikes. So, you can modify the default recommendation playlist but, out of the box, the default is not targetted at particular users.
Last.fm bases its recommendations as to what you might enjoy hearing based not on any intrinsic attributes of a song or artist, but rather on the proximity of songs to each other in a social space. For instance, if two users share a taste in a particular artist (these tastes tracked by a music plug-in for players that pushes played songs to the Last.fm database and presumably weighted by the number of plays) then the sytem assumes that one user would enjoy listening to other songs in the other user's playlist. What I hear is based partly on what those who are close to me in this "taste space" like to listen to. A refinement of the Last.fm model would allow me to assing greater weight to particular users (Last.fm allows me to identify 'friends' but it's not clear whether they are factored into the recommendation algorythm).
Early comparisons of the success rate, (e.g. delivering me a song that I do indeed enjoy) seems to favour Pandora, perhaps not surprising given the heavy-lifting that has gone into creation of the database. Last.fm's recommendations will likely improve as more and more users join-up so that the current occasional perversions (see below) would be swamped out by numbers.
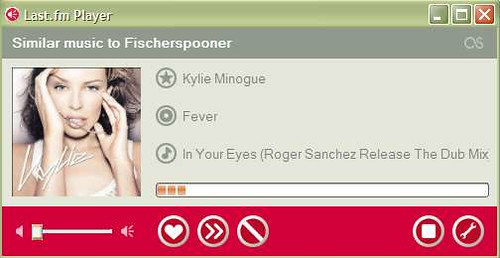
Pandora asks you to provide the name of an artist or song as a starting point. Then, based on its prior analysis of the song or artist, it recommends 'similar' songs that meet the search criteria. Amazingly, the analysis of each song is perfromed by humans
Together our team of thirty musician-analysts have been listening to music, one song at a time, studying and collecting literally hundreds of musical details on every song. It takes 20-30 minutes per song to capture all of the little details that give each recording its magical sound - melody, harmony, instrumentation, rhythm, vocals, lyrics ... and more - close to 400 attributes!
The Pandora player streams these relevant songs and allows you to customize with your likes/dislikes. So, you can modify the default recommendation playlist but, out of the box, the default is not targetted at particular users.
Last.fm bases its recommendations as to what you might enjoy hearing based not on any intrinsic attributes of a song or artist, but rather on the proximity of songs to each other in a social space. For instance, if two users share a taste in a particular artist (these tastes tracked by a music plug-in for players that pushes played songs to the Last.fm database and presumably weighted by the number of plays) then the sytem assumes that one user would enjoy listening to other songs in the other user's playlist. What I hear is based partly on what those who are close to me in this "taste space" like to listen to. A refinement of the Last.fm model would allow me to assing greater weight to particular users (Last.fm allows me to identify 'friends' but it's not clear whether they are factored into the recommendation algorythm).
Early comparisons of the success rate, (e.g. delivering me a song that I do indeed enjoy) seems to favour Pandora, perhaps not surprising given the heavy-lifting that has gone into creation of the database. Last.fm's recommendations will likely improve as more and more users join-up so that the current occasional perversions (see below) would be swamped out by numbers.
Saturday, September 24, 2005
LinkedOut?
How many invites to refer one member of your network to another have you received? Isn't that the real measure of the value of a social network site, e.g. whether it enables connections to be made that would otherwise be impossible?
My network reflects the relationships I already have. If it doesn't enable something more, it's just a glorified contact book (admittedly one in which I get an interesting glimpse of my friends/colleagues job aspirations trough their assertions as to who they are interested in hearing from :-)).
I like LinkedIn and I enjoy the feeling of nurturing my set of connections through invitations to join, but I can't say I've benefited from the supposed 'network effect'.
My network reflects the relationships I already have. If it doesn't enable something more, it's just a glorified contact book (admittedly one in which I get an interesting glimpse of my friends/colleagues job aspirations trough their assertions as to who they are interested in hearing from :-)).
I like LinkedIn and I enjoy the feeling of nurturing my set of connections through invitations to join, but I can't say I've benefited from the supposed 'network effect'.
Thursday, September 22, 2005
It's a Flat Flat World
Reading Thomas Friedman's The World is Flat- centered on how the lowering of trade, political, and technological barriers now allow people to do business with others located all over the world.
For me, one of the most interesting implications of this gloabl connectivity is how the time zone difference between the different regions can be leveraged and taken advantage for increased productivity and efficiency. Friedman cites US hospitals that, overnight, send X-rays to India where they can be read by trained radiologists during normal (Indian) working hours.
I've experienced this sort of time-shifting first hand. My NTT colleague Yuzo Koga and I are co-editors of a specification within the Liberty Alliance's Web Services Framework. The fact that Koga-san and I are on opposite sides/ends of the world (he in Tokyo, myself in Ottawa) proves a blessing whenever we are faced with an editing crunch. When one of us finishes for the day, he simply sends the latest version of the spec to the other, who is just beginning their work day. There is little dead time where the spec is not being actively worked on. The 13 hours between us allow us to work "together" far closer than we ever could in the same city.
It does seem ironic that the book's chosen metaphor for the new geography is one that would actually make impossible this phenomena - if the world really were flat, then there would be no time zones to shift work through.
For me, one of the most interesting implications of this gloabl connectivity is how the time zone difference between the different regions can be leveraged and taken advantage for increased productivity and efficiency. Friedman cites US hospitals that, overnight, send X-rays to India where they can be read by trained radiologists during normal (Indian) working hours.
I've experienced this sort of time-shifting first hand. My NTT colleague Yuzo Koga and I are co-editors of a specification within the Liberty Alliance's Web Services Framework. The fact that Koga-san and I are on opposite sides/ends of the world (he in Tokyo, myself in Ottawa) proves a blessing whenever we are faced with an editing crunch. When one of us finishes for the day, he simply sends the latest version of the spec to the other, who is just beginning their work day. There is little dead time where the spec is not being actively worked on. The 13 hours between us allow us to work "together" far closer than we ever could in the same city.
It does seem ironic that the book's chosen metaphor for the new geography is one that would actually make impossible this phenomena - if the world really were flat, then there would be no time zones to shift work through.
Friday, September 16, 2005
Tag Clouds (or Cloudy Tags)
Seeingthe new home page of Flock got me thinking about whether anything interesting could be done with tag clouds. I wonder if anybody has tried to game the weighting Algorythms to artistic purposes.
Tuesday, September 13, 2005
Descent by Modification
If I was starting over and could choose a different career path, it would be evolutionary genetics. I guess that's why I find myself constantly looking for related analogies within my current career. And so that's why I found the matrix of SAML 2.0 conformant products (as determined by the Liberty Alliance) so interesting, specifically the feature support of HP and Trustgenix.
The rows for HP's Select Federation products and TrustGenix's IdentityBridge product are identical in the SAML 2.0 feature's they support. Given the number of permutations of possible features (even after accounting for the logical dependencies that would decrease the full number), this perfect overlap suggests a relationship between them, just as the large overlap between the DNA of humans and (for instance) chimpanzees indicates an evolutionary relationship between them.
That's why I was so pleased to track down this press release describing just such a relationship - specifically an OEM one. The two products share the same SAML 2.0 feature support because, in a sense, HP's product is descended from that of TrustGenix (at least with respect to support for SAML 2.0).
I'm not suggesting that we are descended from chimps. maybe that's a shame - pygmy chimps (or Bonobos) do seem have to found a gratifying lifestyle.
The rows for HP's Select Federation products and TrustGenix's IdentityBridge product are identical in the SAML 2.0 feature's they support. Given the number of permutations of possible features (even after accounting for the logical dependencies that would decrease the full number), this perfect overlap suggests a relationship between them, just as the large overlap between the DNA of humans and (for instance) chimpanzees indicates an evolutionary relationship between them.
That's why I was so pleased to track down this press release describing just such a relationship - specifically an OEM one. The two products share the same SAML 2.0 feature support because, in a sense, HP's product is descended from that of TrustGenix (at least with respect to support for SAML 2.0).
I'm not suggesting that we are descended from chimps. maybe that's a shame - pygmy chimps (or Bonobos) do seem have to found a gratifying lifestyle.
Monday, September 05, 2005
Universal Identity Grammar
Reading Steven Pinker's Blank Slate again and revisited the concept of Universal Grammar (first proposed by Noam Chomsky)- the posited common underlying rules/infrastructure on which all the world's various languages are built. The theory is that we all have an innate instinct (a language instinct) for these rules and that, based on which specific language we are exposed to as children, various switches are thrown (determined by the environment in which we are raised) that determine the actual manifestation of those rules (e.g. which language we speak as adults). Its asserted that that is why learning a language as an adult is so much more difficult that as a child, you're fighting against the switches that were set long ago.
Universal Grammar suggests that the underlying structures of language, the grammar, is innate and the same for all humans; different languages are the result of some config file in the head of a young child being set with various binary parameters. The simplest illustration of one of these params is the choice of Head first or Head last; depending on which choice is made, a language is either SOV (Subject Object Verb) or SVO (Subject Verb Object) with many associated orderings in other aspects of syntax. For instance, Japanese is a SOV language and English is typically SVO. In Japanese, the verb always appears at the end of clauses and sentences (a fact which makes my sometimes attempts to learn the rudiments of Nihongo interesting).
Given the recently introduced concept of an identity 'metaystem', the idea of some set of fundamental set of rules and/or components, from which various identity applications can build, seems appropo. Just as languages differ in their particular manifestation of the Universal Grammer, particular identity systems will inevitably vary in their manifestation of the basic underlying components and principles.
I can imagine that in the 'mind' of every young SSO architecture, there is a config file with switches for 'front-channel vs back-channel', 'remote or local storage', '3rd party or self assertions', etc. The specifics of the environment in which that architecture (e.g. B2B, constrained client, privacy requirements, legislative issues) grows to maturity determine how the various parameters are set, and consequently the use cases for which that architecture is appropriate as an 'adult'.
So I guess we shouldn't feel bad about favouring one federated identity architecture over another - it's just that we are adults and our switches were set long ago.
Universal Grammar suggests that the underlying structures of language, the grammar, is innate and the same for all humans; different languages are the result of some config file in the head of a young child being set with various binary parameters. The simplest illustration of one of these params is the choice of Head first or Head last; depending on which choice is made, a language is either SOV (Subject Object Verb) or SVO (Subject Verb Object) with many associated orderings in other aspects of syntax. For instance, Japanese is a SOV language and English is typically SVO. In Japanese, the verb always appears at the end of clauses and sentences (a fact which makes my sometimes attempts to learn the rudiments of Nihongo interesting).
Given the recently introduced concept of an identity 'metaystem', the idea of some set of fundamental set of rules and/or components, from which various identity applications can build, seems appropo. Just as languages differ in their particular manifestation of the Universal Grammer, particular identity systems will inevitably vary in their manifestation of the basic underlying components and principles.
I can imagine that in the 'mind' of every young SSO architecture, there is a config file with switches for 'front-channel vs back-channel', 'remote or local storage', '3rd party or self assertions', etc. The specifics of the environment in which that architecture (e.g. B2B, constrained client, privacy requirements, legislative issues) grows to maturity determine how the various parameters are set, and consequently the use cases for which that architecture is appropriate as an 'adult'.
So I guess we shouldn't feel bad about favouring one federated identity architecture over another - it's just that we are adults and our switches were set long ago.
Wednesday, July 27, 2005
Necessity is the mother of submission
Kim Cameron writes that WS-SecurityPolicy has been published, presumably in anticipation of the formation of the OASIS Technical Committee that will be formed for its progression.
This is the first time I've heard it acknowledged that Infocard's requirements are driving Microsoft's submission schedule. Makes sense for them but why is IBM so willing to wait?
Another key piece of enabling infrastructure for Infocard is WS-Trust and its another of the three being submitted. The immediate relevance of WS-SecureConversation is less clear to me - perhaps Infocard is facilitating the IDP and SP establishing secure session keys?
Additionally, most attention focusses on WS-Trust. But Infocard wouldn't get out of the box as an 'identity selector' if it wasn't provided with the criteria to be used for selecting. This implies policy and that implies WS-Policy (currently missing from the submission) & WS-SecurityPolicy.
Today WS-SecurityPolicy, which is an important specification needed to build components that support InfoCards, was published
This is the first time I've heard it acknowledged that Infocard's requirements are driving Microsoft's submission schedule. Makes sense for them but why is IBM so willing to wait?
Another key piece of enabling infrastructure for Infocard is WS-Trust and its another of the three being submitted. The immediate relevance of WS-SecureConversation is less clear to me - perhaps Infocard is facilitating the IDP and SP establishing secure session keys?
Additionally, most attention focusses on WS-Trust. But Infocard wouldn't get out of the box as an 'identity selector' if it wasn't provided with the criteria to be used for selecting. This implies policy and that implies WS-Policy (currently missing from the submission) & WS-SecurityPolicy.
Friday, July 15, 2005
Any friend of mine ....
This is a new one for me. A friend/colleague of mine just emailed me to say 'sorry, but I have to disconnect from you on LinkedIn'.
I assumed it was because their employer discouraged employees from participating in such social networks and said so. My friend said 'No, its your network' and then, without giving any real details, simply explained that it was 'personal, but nothing to do with you'.
This of course has me analyzing my network, looking at its members, and making wild guesses as to what sort of horrible and upsetting incident would cause somebody to give up a connection with somebody as dynamic and well-thought of in the industry as I am. A spilled drink at a hospitality suite? Perhaps a cab fare split unequally?
I think I'll wait to share this precedent with my wife - she's never liked my friends.
I assumed it was because their employer discouraged employees from participating in such social networks and said so. My friend said 'No, its your network' and then, without giving any real details, simply explained that it was 'personal, but nothing to do with you'.
This of course has me analyzing my network, looking at its members, and making wild guesses as to what sort of horrible and upsetting incident would cause somebody to give up a connection with somebody as dynamic and well-thought of in the industry as I am. A spilled drink at a hospitality suite? Perhaps a cab fare split unequally?
I think I'll wait to share this precedent with my wife - she's never liked my friends.
Thursday, July 07, 2005
Six Degress of SPeration?

The “six degrees” theory contends that any human being in the world can be “connected” to another human being by a path traceable through about no more than six different people.
Early research suggested that the Web's version of the rule was '19 degress of separation", i.e. that any one Web site is no more than about 19 "clicks” away from any other site.
In 2000 however, IBM, Altavista, and Compaq discovered that the Web isn't so connected. When you can get from one to another, it's about 19 clicks, but sometimes 'you can't get there from here'.
The connected Web was found to be divided into four parts (their combined shape usually described as a "bow tie")
- the central, highly connected core or knot of the bow tie, where pages have hyperlinks to *and* from other pages in the core
- one section adjacent to the core (one loop of the bow), where pages have hyperlinks into the core pages but not from them
- another section adjacent to the core (the other loop of the bow), where pages have links from the core pages but not into them
- the tendrils (the straps of the bow tie) abutting the loop sections, where pages have links either into pages that have no link into core pages or from pages that have no link from core pages
This topography results from the Web being a directed graph, connections between nodes have directions. For the Web, its the fact that HTML's <a href=""> mechanism is one-sided.
The network created between sites/providers by the fact of some issuing identity tokens (identity providers) and some choosing to rely on them (service providers) is also directed; one site might issue assertions to another but this is not to say that the reciprocal relationship would exist. Additionally, a site might act as an identity provider in some transactions and a service provider for others.
Consequently, I expect there will be a similar "bow tie" topography for the "provider network". By analogy, there should be:
- a strongly connected central knot where it would be possible to jump from any one to another (but not for any one particular user)
- the "IN" loop in which there are identity providers who will issue identity tokens to sites in the central core, but not accept tokens from any in the core (the major portals like AOL)
- the "OUT" loop in which there are service providers who will accept identity tokens from core providers but not issue them (presumably the vast majority of sites)
- islands of isolated CoTs
Given that we are starting with isolated CoTs, it should be interesting to see the network evolve. Islands will be connected together through one CoT member establishing the necessary business agreements with a provider in another CoT.
Wednesday, July 06, 2005
When phishers dream ...
Foopad is an aggregation service for social sites - comparable to Yodlee in the financial space. Foopad allows you to mash-up the various social sites like Flikr, 43things, and del.icio.us, agrregating your content from each service into a single interface (using the APIs each of those services offer rather than screen scraping I believe).
It's cool but there is a price. To aggregate your content, you have to enter your account name and password for each service (once more just like Yodlee). Below is the interface prompting me for my account details for 43things.
When phishers dream at night, surely it must be of pulling something like this off, i.e. getting people to present all their account data in a nice tidy package.
Strangely enough, Foopad does seem to recognize the value of a federated model as they are listed as using OpenID between their subsites.
It's cool but there is a price. To aggregate your content, you have to enter your account name and password for each service (once more just like Yodlee). Below is the interface prompting me for my account details for 43things.
When phishers dream at night, surely it must be of pulling something like this off, i.e. getting people to present all their account data in a nice tidy package.
Strangely enough, Foopad does seem to recognize the value of a federated model as they are listed as using OpenID between their subsites.
Tuesday, July 05, 2005
Passwords as Global identifiers
There seems to be a perception in the industry that federated identity, in that it connects together previously isolated web sites, will only contribute to the identity theft problem by exacerbating the ramifications of any successful attack. Break one link through a phish or otherwise, and the whole chain is yours (with a little trial and error).
But, most users reuse passwords across the various sites they deal with (the more sophisticated may not exactly reuse the same password but rather have some scheme for generating memorable passwords from some seed and the site name in question).
So, in a sense, the accounts of many users at their different providers are already linked - linked through the duplicated passwords those users have at the different sites.
But, most users reuse passwords across the various sites they deal with (the more sophisticated may not exactly reuse the same password but rather have some scheme for generating memorable passwords from some seed and the site name in question).
So, in a sense, the accounts of many users at their different providers are already linked - linked through the duplicated passwords those users have at the different sites.
Vector Addition for Identifiers
Kim Cameron's 4th Law of Identity deals with directional identifiers
As explanation, "identity has direction, not just magnitude".
In math, something specified by both a direction and a magnitude is called a vector and are usually represented by an arrow pointing in the appropriate direction with a length corresponding to the magnitude. Like normal objects with just magnitude (scalars), two vectors can be added together. But, the addition has to take into account the direction of both vectors. To add vector A to vector B, the tail of B is joined to the head of A, the arrow from the tail of A to the head of B is the resultant sum.
The relevance of vector addition to federated identifiers is that 'adding' two identifiers for a user must also take into account their direction, i.e. the provider(s) for which the identifiers are targetted. Federated identifiers only make sense when qualified by the entities that will recognize them and be able to map them into some local account.
In many situations, a service provider may have a shared identifier for a given user with an identity provider and the identity provider may have a (different, when privacy is required) shared identifier with another service provider for the same user. If the first and second service providers are to communicate on behalf of the user, they need a means to refer to that user. Assuming that the two servie providers don't wish to themselves establish a permanent shared identifier, the identity provider can help by mapping from the first identifier to the second. The first provider asks the identity provider for an appropriate identifier to use when talking to the second service provider about the user in question, and the identity provider returns the appropriate identifier that the second provider will recognize (likely encrypted for the second provider).
If the identifier shared between the first service provider and the identity provider is vector A, and that shared between the identity provider and the second service provider is vector B, the mapped (and encrypted result) is logically equivalent to the sum - vector A+B.
This is shown in the diagram (using different terminology - web service consumer (WSC) and web service provider (WSP) for the first and second service providers and security token service (STS) for the identity provider).
A universal identity system must support both "omni-directional" identifiers for use by public entities and "unidirectional" identifiers for use by private entities, thus facilitating discovery while preventing unnecessary release of correlation handles.
As explanation, "identity has direction, not just magnitude".
In math, something specified by both a direction and a magnitude is called a vector and are usually represented by an arrow pointing in the appropriate direction with a length corresponding to the magnitude. Like normal objects with just magnitude (scalars), two vectors can be added together. But, the addition has to take into account the direction of both vectors. To add vector A to vector B, the tail of B is joined to the head of A, the arrow from the tail of A to the head of B is the resultant sum.
The relevance of vector addition to federated identifiers is that 'adding' two identifiers for a user must also take into account their direction, i.e. the provider(s) for which the identifiers are targetted. Federated identifiers only make sense when qualified by the entities that will recognize them and be able to map them into some local account.
In many situations, a service provider may have a shared identifier for a given user with an identity provider and the identity provider may have a (different, when privacy is required) shared identifier with another service provider for the same user. If the first and second service providers are to communicate on behalf of the user, they need a means to refer to that user. Assuming that the two servie providers don't wish to themselves establish a permanent shared identifier, the identity provider can help by mapping from the first identifier to the second. The first provider asks the identity provider for an appropriate identifier to use when talking to the second service provider about the user in question, and the identity provider returns the appropriate identifier that the second provider will recognize (likely encrypted for the second provider).
If the identifier shared between the first service provider and the identity provider is vector A, and that shared between the identity provider and the second service provider is vector B, the mapped (and encrypted result) is logically equivalent to the sum - vector A+B.
This is shown in the diagram (using different terminology - web service consumer (WSC) and web service provider (WSP) for the first and second service providers and security token service (STS) for the identity provider).
Monday, July 04, 2005
Misnomer - by Elisa Korenne
Elisa Korentayer was until very recently a key part of the human infrastructure that keeps the Liberty Alliance running. Elisa served in a variety of roles, most recently as the Program Manager for the Public Policy Expert Group (where, through my interactions with PPEG, I can attest to the incredible job she did).
Elisa has left Liberty to concentrate on her music career (using the pseudonym Elisa Korenne) but, before her departure, she penned the following lyrics (likely after some session on ID Theft)
I feel compelled to mention that, in the Liberty model, mere possession of a federated identifier for a user does not guarantee an attacker the ability to impersonate that user. I expect Elisa intentionally kept well clear of the need to rhyme with 'pairwise opaque'.
Elisa has left Liberty to concentrate on her music career (using the pseudonym Elisa Korenne) but, before her departure, she penned the following lyrics (likely after some session on ID Theft)
Misnomer
(c) 2005 Elisa Korenne
Commerce drowns the sorrows
A name makes you a man
I left mine in the storehouse
I go visit when I can
I go visit when I can
Couldn’t see past the windows
Left the X on the map
Then you took my measure and my name
I wish you’d also take the rap
I wish you’d also take the rap
I forgot the password
I forgot the key
I left my name in the storehouse
Now there’s nothing left of me
Now I’m stuck behind the doorjam
This collar is too tight
An old bottle in the hay
A locked door to my right
A locked door to my right
I forgot the password
I forgot the key
I left my name in the storehouse
Now there’s nothing left of me
I left my name in the storehouse
With the Spanish brew and my clothes
Now I sleep in straw and iron
And weep in the watering hole
And weep in the watering hole
I forgot the password
I forgot the key
I left my name in the storehouse
Now there’s nothing left of me
There’s a name for every person
There’s a name for what you pulled
My name now has two owners
Your misnomer’s got them fooled
Yeah, your misnomer’s got them fooled
I feel compelled to mention that, in the Liberty model, mere possession of a federated identifier for a user does not guarantee an attacker the ability to impersonate that user. I expect Elisa intentionally kept well clear of the need to rhyme with 'pairwise opaque'.
Personalized Graphics for Password Fields
Referring to a paper describing a scheme for using 'dynamic security skins' as a defense against phishing attacks, Ben Hyde writes "This is a perfect opportunity for a grease monkey script!"
The following simple script demonstrates the principle of using user-specific graphics to simplify server authentication (while in no way implementing the full system outlined in the paper Ben references).
For trusted sites (mock ones listed below under '@include'), a user-chosen graphic (here my Flikr logo), is used as the background image for the password field. The effect is shown in the graphic above, it's a capture of the password interface for one of my trusted sites with a visual cue to that effect (the alternating purple-bands are an artifact of the dimensions of my logo).
//
// ==UserScript==
// @name Personalized Password Fields
// @description Displays user-chosen graphic in trusted password fields
// @include https://*.bank-a.com/*
// @include https://*.bank-b.com/*
// ==/UserScript==
function addStyle(css) {
var head, style;
head = document.getElementsByTagName('head')[0];
if (!head) { return; }
style = document.createElement('style');
style.type = 'text/css';
style.innerHTML = css;
head.appendChild(style);
}
var backg = "input[type='password'] { background: url(http://photos6.flickr.com/buddyicons/25436942@N00.jpg?1110378496) }";
addStyle(backg);
Wednesday, June 29, 2005
Feedback to prevent ID Theft
Researchers at Stanford are looking at ways in which drivers could be encouraged to not speed.
Assuming that this sort of feedback wouldn't do much to discourage a phisher from sending an attack (it would be difficult to convince them to attach electrodes to their fingers for instance), perhaps it could be used to alert the recipient of the potential dangers of "clicking on the URL"?
As the idea of simple visual indicators to show the risk level of emails has been done, perhaps:
The domains covered in the idea space included foregrounding of information to increase awareness, visual and audio notification, providing haptic feedback (accentuating real-world effects), reputation systems (publicizing driver reputation / behavior), offering trade-offs (gas consumption, speeding tickets), rewards and incentives (insurance incentives for monitoring), and playing on emotions.
Assuming that this sort of feedback wouldn't do much to discourage a phisher from sending an attack (it would be difficult to convince them to attach electrodes to their fingers for instance), perhaps it could be used to alert the recipient of the potential dangers of "clicking on the URL"?
As the idea of simple visual indicators to show the risk level of emails has been done, perhaps:
- mouse vibration alerts recipient of risk (maybe for really obvious phsishes the mouse just refuses to work and sits their shaking crazily?)
- paying users to NOT click on URLs in suspicious emails.
- dynamic graphic showing their bank account balance dropping
- publicly listing those who do fall prey
Wednesday, June 22, 2005
Liberty ID-WSF is an identity metasystem
Already with ID-WSF 1.1, but to a greater extent with upcoming ID-WSF 2.0, Liberty's Web Services Framework meets the logical requirements of (at least part of) an identity metasystem.
From Microsoft's whitepaper explaining their vision (my emphasis below):
and
In ID-WSF, the 'technology' that is (currently) allowed to be different between the two providers, and that can be 'translated' to some extent, are security tokens. The web service provider (WSP) can, when it registers its service at the Discovery Service (DS), indicate which security token formats it expects (e.g. SAML, X.509, bearer, etc). When a client WSC) subsequently queries the DS for available services, it can also indicate which token formats it can support. It is the DS that looks for an intersection between the two different sets of security tokens and (acting as an STS) provides an appropriate token format to the WSC for inclusion in its subsequent request to the WSP.
Additionally, the DS may need to perform some translation between the security token that the WSC presents it as part of its discovery query and that which the DS returns to the WSC for inclusion in the request to the WSP. For instance, the WSC may present in its discovery query a SAML 1.1 assertion that it received from an IDP through ID-FF based SSO. If the relevant WSP (that being discovered by the WSC) only supports SAML 2.0 assertions, then the DS will have to translate from SAML 1.1 to SAML 2.0 to ensure that this WSP gets what it needs.
Admittedly, this level of flexibility on security token formats is not the wide-open freedom of different providers being able to choose different protocol stacks. But there is a price to be paid for that freedom.
From Microsoft's whitepaper explaining their vision (my emphasis below):
The Identity Metasystem is an interoperable architecture for digital identity that assumes people will have several digital identities based on multiple underlying technologies, implementations, and providers.
and
The metasystem enables identities provided by one identity system technology to be used within systems based on different technologies, provided an intermediary exists that understands both technologies and is willing and trusted to do the needed translations.
In ID-WSF, the 'technology' that is (currently) allowed to be different between the two providers, and that can be 'translated' to some extent, are security tokens. The web service provider (WSP) can, when it registers its service at the Discovery Service (DS), indicate which security token formats it expects (e.g. SAML, X.509, bearer, etc). When a client WSC) subsequently queries the DS for available services, it can also indicate which token formats it can support. It is the DS that looks for an intersection between the two different sets of security tokens and (acting as an STS) provides an appropriate token format to the WSC for inclusion in its subsequent request to the WSP.
Additionally, the DS may need to perform some translation between the security token that the WSC presents it as part of its discovery query and that which the DS returns to the WSC for inclusion in the request to the WSP. For instance, the WSC may present in its discovery query a SAML 1.1 assertion that it received from an IDP through ID-FF based SSO. If the relevant WSP (that being discovered by the WSC) only supports SAML 2.0 assertions, then the DS will have to translate from SAML 1.1 to SAML 2.0 to ensure that this WSP gets what it needs.
Admittedly, this level of flexibility on security token formats is not the wide-open freedom of different providers being able to choose different protocol stacks. But there is a price to be paid for that freedom.
Thursday, June 16, 2005
Social lists
I use Webjay alot for streaming music. The site allows you to define playlists of (legally) downloadable MP3s. The playlists you create are connected to others that share the same songs. The resulting network is a great way to discover new music - there is a better chance that I'll like a song that somebody else likes if I know that we already share tastes in music.
So I get exposed to lots of great new music and artists. Oftentimes, as I listen, I think 'X would like that' where X is some friend of mine. As it stands now, I manually send an email to X with a link to the song in question. This is less than ideal as there is no record of the connection for future reference and X has to keep track of these sorts of 'invitations'.
I think there is value in the idea of people defining lists (songs, bookmarks, radio stations, geolocations, etc) FOR others rather than themselves.
A system which exposes people to new things (e.g. music, sites, etc) would be valuable - that's the problem with sites like iTunes - you have this wealth of great music that you just know has songs you will love, but but don't know how to get to them.
What your friends think would be interesting "to you" would be a valuable entry point (far more than some untargetted 'Whats popular')
So I get exposed to lots of great new music and artists. Oftentimes, as I listen, I think 'X would like that' where X is some friend of mine. As it stands now, I manually send an email to X with a link to the song in question. This is less than ideal as there is no record of the connection for future reference and X has to keep track of these sorts of 'invitations'.
I think there is value in the idea of people defining lists (songs, bookmarks, radio stations, geolocations, etc) FOR others rather than themselves.
A system which exposes people to new things (e.g. music, sites, etc) would be valuable - that's the problem with sites like iTunes - you have this wealth of great music that you just know has songs you will love, but but don't know how to get to them.
What your friends think would be interesting "to you" would be a valuable entry point (far more than some untargetted 'Whats popular')
Tuesday, June 14, 2005
TUID (Torah Unique Identifiers)
This Wired article discusses how, to complicate the trafficking of stolen Torahs, two rival registries have been established.
Historially, it has been the "anonymity" of Torah scrolls that facilitates the fencing of stolen scrolls.
Because in the past there has been no way to verify whether or nor a particular Torah is 'hot' (because there has been no way to label it), thieves have had an easy time selling stolen scrolls to unsuspecting congregations.
The two registries, the Universal Torah Registry and the International Torah Registry take different approaches to identifying individual Torahs in a manner that doesn't violate rabbinic law - the first by a unique pattern of pin pricks, the second by an analysis of various distinguishing features (e.g. line spacing etc ).
These TUIDs (Torah Unique Identifiers) are global. Do not Torahs also deserve privacy protection? Seems there would be an opportunity for federated identity management between the two registries.
Historially, it has been the "anonymity" of Torah scrolls that facilitates the fencing of stolen scrolls.
Torah scrolls are inherently anonymous. Jewish law dictates that not one character can be added to the 304,805 letters of the Torah's text. That means no "property of" stamps, no serial numbers, no visible identifying marks of any kind.
Because in the past there has been no way to verify whether or nor a particular Torah is 'hot' (because there has been no way to label it), thieves have had an easy time selling stolen scrolls to unsuspecting congregations.
The two registries, the Universal Torah Registry and the International Torah Registry take different approaches to identifying individual Torahs in a manner that doesn't violate rabbinic law - the first by a unique pattern of pin pricks, the second by an analysis of various distinguishing features (e.g. line spacing etc ).
These TUIDs (Torah Unique Identifiers) are global. Do not Torahs also deserve privacy protection? Seems there would be an opportunity for federated identity management between the two registries.
Wednesday, June 08, 2005
What SPF factor would you use?
Sun's Eve Maler followed up on a Tim Bray (also of Sun) post on 'research' that indicated that sun exposure wasn't necessarily bad:
I expect this is neither the official Sun line:
Personally, I value my sun exposure and so will not take any dramatic measures to protect myself in future standards meetings.
I have long been suspicious of answers to the question of how much sun exposure is good/bad for you.
I expect this is neither the official Sun line:
- on being an employee, or
- on the MSFT/Sun relationship
Personally, I value my sun exposure and so will not take any dramatic measures to protect myself in future standards meetings.
PAOS
Eve Maler suggested an alternative shibboleth for distinguishing the SAML community from others - namely the pronunciation of 'PAOS'.
Eve points out that the shibboleth I had proposed - 'back-channel' - was originally introduced by Liberty and so it doesn't serve to distinguish SAML from Liberty. While not ignoring the differences, I actually think of Liberty as part of the 'SAML tribe' - fundamental as SAML is to the LAP architecture.
Eve postulates that:
in SAML discussions, this is usually pronounced “pay-oss". But in Liberty meetings, it’s pronounced “paah-ose” – by some of the same people.
I'm at a Liberty meeting right now so I'm going to start keeping track of how people say 'paos' , results to come.
Eve points out that the shibboleth I had proposed - 'back-channel' - was originally introduced by Liberty and so it doesn't serve to distinguish SAML from Liberty. While not ignoring the differences, I actually think of Liberty as part of the 'SAML tribe' - fundamental as SAML is to the LAP architecture.
Eve postulates that:
in SAML discussions, this is usually pronounced “pay-oss". But in Liberty meetings, it’s pronounced “paah-ose” – by some of the same people.
I'm at a Liberty meeting right now so I'm going to start keeping track of how people say 'paos' , results to come.
Monday, June 06, 2005
QWERTY
Never was a blog title easier to type. Of course, it was easy because the keyboard is arranged to make it so.
The name "QWERTY" for our typewriter keyboard comes from the first six letters in the top alphabet row. It was invented by C. L. Sholes, who put together the prototypes of the first commercial typewriter in a Milwaukee machine shop back in the 1860's.
As the (possibly apocryphal) story goes, the Qwerty design has little to do with modern efficiency - rather being optimally inefficient. The layout was designed to keep frequently used letter pairs (E and D or T and H) relatively far apart so that typists wouldn't hit them in quick succession, jamming primitive machines. Typists on early models were too fast!, by rearranging the keyboard Sholes was able to slow them down.
This interpretation of course misses the point. By arranging the keys in this manner Sholes almost certainly enabled faster typing as the typist wouldn't have to repeatedly stop and clear the keys. Qwerty was the (or at least one of) optimal design given the limitations of the striking technology at the time. It was only when the technology moved forward (e.g. those cool balls, and now PCs) that the designed limitation of Qwerty became irrelevant and sub-optimal. Until that point, the limitations of Qwerty enabled an overall more efficient system.
XML is almost certainly a sub-optimal syntax if the criteria are only on-the-wire speed and processing efficiency. Nevertheless, XML's advantages over binary formats (ASN.1 etc) in inspection and transformation outweigh the disadvantages. Overall, when taking into account design, development, testing etc, XML enables a more efficient system.
So XML is the Qwerty keyboard of this IT era. It may not be perfect but it's better than the alternatives.
The name "QWERTY" for our typewriter keyboard comes from the first six letters in the top alphabet row. It was invented by C. L. Sholes, who put together the prototypes of the first commercial typewriter in a Milwaukee machine shop back in the 1860's.
As the (possibly apocryphal) story goes, the Qwerty design has little to do with modern efficiency - rather being optimally inefficient. The layout was designed to keep frequently used letter pairs (E and D or T and H) relatively far apart so that typists wouldn't hit them in quick succession, jamming primitive machines. Typists on early models were too fast!, by rearranging the keyboard Sholes was able to slow them down.
This interpretation of course misses the point. By arranging the keys in this manner Sholes almost certainly enabled faster typing as the typist wouldn't have to repeatedly stop and clear the keys. Qwerty was the (or at least one of) optimal design given the limitations of the striking technology at the time. It was only when the technology moved forward (e.g. those cool balls, and now PCs) that the designed limitation of Qwerty became irrelevant and sub-optimal. Until that point, the limitations of Qwerty enabled an overall more efficient system.
XML is almost certainly a sub-optimal syntax if the criteria are only on-the-wire speed and processing efficiency. Nevertheless, XML's advantages over binary formats (ASN.1 etc) in inspection and transformation outweigh the disadvantages. Overall, when taking into account design, development, testing etc, XML enables a more efficient system.
So XML is the Qwerty keyboard of this IT era. It may not be perfect but it's better than the alternatives.
Wednesday, June 01, 2005
Aromotherapy for ID Theft
Wired reports that users, when exposed to the neuropeptide oxytocin
are more apt to feel 'trust'.
Researchers at the University in Switzerland in Zurich put the theory to the test and found that 45 percent of the oxytocin sniffers displayed what the scientists determined to be the "highest level of trust" with their money. Only 21 percent of those in the placebo group were as trusting.
Other research confirms the findings.
This suggests a new tack on id theft. A Firefox GreaseMonkey script that, on browser access to a quesitonable site, releases a small puff of 'oxytocin inhibitor' (surely there is one?) The otherwis naive and trusting user, after inhaling, would experience a strong sense of fear, uncertainty, and doubt. Instead of obediently providing their password, they back slowly away from the computer, shaking their head in confusion.
Hopefully the effect wears off before their spouse gets home. That sort of refinement will have to wait for v2.
are more apt to feel 'trust'.
Researchers at the University in Switzerland in Zurich put the theory to the test and found that 45 percent of the oxytocin sniffers displayed what the scientists determined to be the "highest level of trust" with their money. Only 21 percent of those in the placebo group were as trusting.
Other research confirms the findings.
This suggests a new tack on id theft. A Firefox GreaseMonkey script that, on browser access to a quesitonable site, releases a small puff of 'oxytocin inhibitor' (surely there is one?) The otherwis naive and trusting user, after inhaling, would experience a strong sense of fear, uncertainty, and doubt. Instead of obediently providing their password, they back slowly away from the computer, shaking their head in confusion.
Hopefully the effect wears off before their spouse gets home. That sort of refinement will have to wait for v2.
Art thou a SAML'ite?
Notwithstanding its most recent manifestation, a shibboleth is a word or phrase that can be used to distinguish one group of speakers from another, typically through pronunciation. In the Bible, the Gileads used the fact that the dialect of the people of Ephraim did not include the 'sh' sound. Consequently, when an Ephraimite was challenged to say 'Shibboleth', it came out as 'sibboleth'. The Ephraimite was thereby identified and quickly slain (slewed, smite ?).
In World War II, the Finnish underground took advantage of the complete unpronounceability of their language (e.g. Nokia) to ferret out infiltrators. Our Canadian border officers now use the pronunication of 'out and about' in a similar manner.
Shibboleths are not always used in such a prejudicial and divisive manner. By identifying differences they can serve as focus point for dialog and self-improvement. For instance, Americans pronounce the last letter of the English alphabet 'zee', the entire rest of the world, as was intended, says 'zed'. Throughout history, many awkward situations have been defused because of this humourous distinction.
In this spirit of the word, e.g. acting to bring people together through self-awareness of their differences, I propose here a shibboleth for distinguishing the SAML community from other federated identity management initiatives, namely the term 'back-channel'.
For SAML'ites, the term refers to a SOAP-message channel between providers, distinguished from a browser-intermediated 'front-channel'. Other federated identity proposals either have no corresponding channel in their architectures or, if present, do not describe it in this manner.
Other, less technical, interpretations for "back-channel" are also possible and thereby make 'back-channel' an option for the desired shibboleth between the tribe of SAML and others. If you are unable to say/write 'back-channel' without your mind straying to such alternative interpretations, then you cannot be of the SAML tribe.
With increased awareness of this fundamental differentiator amongst its members, the federated identity community can now move forward and tackle the more significant issues that confront us. As my analysts like to say, the first step to getting better is admitting you have a problem.
Sunday, May 22, 2005
Forced Moves in Identity Space (or 'the Web made me do it')
Evolutionary scientists find it useful to contemplate the set of all creatures past, present, and future as part of an infinite design space (referred to by the natural philospher Daniel Dennett as the "Library of Mendel" in his book Darwin's Dangerous Idea - this a tribute to Gregor Mendel and his pea pods).
The idea is that particular species occupy (or occupied) specific positions in this design space, characterized by their values along an infinite set of axes (e.g. leg length, number of digits, etc). Evolution is then seen as movement through this space, the set of ooordinates for a species changing (smoothly or more jerkily depending on your theory) as time goes by.
Within this vast space there are some points (or more accurately lines) that have been occupied more times than mere chance would suggest is appropriate. Some features of living creatures are 'forced moves', i.e. things so obvious that we aren't surprised to see them repeated across many different animals and so repeatedly hit upon in design space. Examples include bilateral body symmetry, two eyes for stereo vision, mouth at the front of the body, etc.
When we see such forced moves in different creatures, we don't have to assume any special relationship betwen those animals, it's enough to know that the animals deal or dealt with similar environments and constraints and have independently come across the unavoidable wisdom of the forced move. For instance, otters and dolphins both have body shapes that are suited for moving around underwater but we don't have to believe that one evolved from the other (or from some recent shared ancestor) because of this similarity. Streamlining just makes sense when you spend alot of time underwater.
Some features of SSO suites are forced moves, e.g. things so obvious that we aren't surprised when multiple suites take advantage of them. Examples include HTTP redirects, URL parameters, HTML Form POSTS, SOAP-messaging, claiming to be user-centric, etc. Taking advantage of that which the common infrastructure provides just makes sense.
If however, we saw very similar features in different SSO suites for which it could not be claimed that both protocols were forced to that choice, then we would be justified in assuming that there was some sort of relationship between them, most likely through descent (acknowledged or otherwise).
For instance, Liberty defined the Authentication Context mechanism in itsID-FF. There is very similar functionality in SAML 2.0. Consequently, it's not surprising that the functionality in SAML 2.0 is directly descendant from that in ID-FF 1.2 (through Liberty's contribution of ID-FF 1.2 as input to SAML 2.0). It would be surprising (even suspicious) to see two so similar mechanisms in different SSO suites without such a relationship because authentication context doesn't feel like a forced move.
Why does this matter? The more forced moves there are, the greater will be the similarities between the different SSO suites (e.g. SAML 1.1, ID-FF 1.2, SAML 2.0, WS-Federation, SxiP, LID, etc) and the less fundamental the differences. The more trivial the differences, the greater the chances of interoperability between them.
The idea is that particular species occupy (or occupied) specific positions in this design space, characterized by their values along an infinite set of axes (e.g. leg length, number of digits, etc). Evolution is then seen as movement through this space, the set of ooordinates for a species changing (smoothly or more jerkily depending on your theory) as time goes by.
Within this vast space there are some points (or more accurately lines) that have been occupied more times than mere chance would suggest is appropriate. Some features of living creatures are 'forced moves', i.e. things so obvious that we aren't surprised to see them repeated across many different animals and so repeatedly hit upon in design space. Examples include bilateral body symmetry, two eyes for stereo vision, mouth at the front of the body, etc.
When we see such forced moves in different creatures, we don't have to assume any special relationship betwen those animals, it's enough to know that the animals deal or dealt with similar environments and constraints and have independently come across the unavoidable wisdom of the forced move. For instance, otters and dolphins both have body shapes that are suited for moving around underwater but we don't have to believe that one evolved from the other (or from some recent shared ancestor) because of this similarity. Streamlining just makes sense when you spend alot of time underwater.
Some features of SSO suites are forced moves, e.g. things so obvious that we aren't surprised when multiple suites take advantage of them. Examples include HTTP redirects, URL parameters, HTML Form POSTS, SOAP-messaging, claiming to be user-centric, etc. Taking advantage of that which the common infrastructure provides just makes sense.
If however, we saw very similar features in different SSO suites for which it could not be claimed that both protocols were forced to that choice, then we would be justified in assuming that there was some sort of relationship between them, most likely through descent (acknowledged or otherwise).
For instance, Liberty defined the Authentication Context mechanism in itsID-FF. There is very similar functionality in SAML 2.0. Consequently, it's not surprising that the functionality in SAML 2.0 is directly descendant from that in ID-FF 1.2 (through Liberty's contribution of ID-FF 1.2 as input to SAML 2.0). It would be surprising (even suspicious) to see two so similar mechanisms in different SSO suites without such a relationship because authentication context doesn't feel like a forced move.
Why does this matter? The more forced moves there are, the greater will be the similarities between the different SSO suites (e.g. SAML 1.1, ID-FF 1.2, SAML 2.0, WS-Federation, SxiP, LID, etc) and the less fundamental the differences. The more trivial the differences, the greater the chances of interoperability between them.
Saturday, May 21, 2005
Another use for Java?
Ben Hyde (Ben, we miss you in TEG) drew my attention to a VI reference coffee mug.
As user-centric identity management seems hot these days, perhaps we should expect to soon see something similar for SAML.
Interesting scenarios emerge.
Ok, let's see, I am a 'Senior Manager', I guess I'm supposed to use the <AttributeStatement> for that. Namespace? What the &&#$@*%$^# is a namespace. Oh jeez, I have to sign this thing, where did I put my private key? I just had it this morning.
A WS-Federation reference would be simpler. Perhaps a shot glass would suffice?
As user-centric identity management seems hot these days, perhaps we should expect to soon see something similar for SAML.
Interesting scenarios emerge.
Ok, let's see, I am a 'Senior Manager', I guess I'm supposed to use the <AttributeStatement> for that. Namespace? What the &&#$@*%$^# is a namespace. Oh jeez, I have to sign this thing, where did I put my private key? I just had it this morning.
A WS-Federation reference would be simpler. Perhaps a shot glass would suffice?
Lamarck Lives!
Jean-Baptiste Lamarck was the 19th century natural philosopher who is now best known for his much derided theory of evolution.
Lamarck postulated that animals acquire characteristics through their experiences and, importantly, these characteristics can be passed onto their offspring. The archetypical example is that the giraffe developed such a long neck through successive generations of animals extending their necks to get to the tender leaves on the higher branches of trees. Each generation saw the necks get a little bit longer as the animals continued to stretch out. The efforts of one generation were manifested in the next, the offspring benefited from what their parents had attempted.
Lamerck's theory - this inheritance of acquired characteristics is now widely refuted (including through experiments that had the tails of mice cut off for generations and yet they continued to be present on babies). Darwin's theory of natural selection is now accepted as the true driver of evolution.
.NET Passport is Microsoft's now much derided web-based identity management scheme that never really reached the potential that Microsoft seemed to imagine for it. .NET Passport spent its life in an environment of mistrust (e.g. why would I share my credit card with Microsoft) and privacy concerns (e.g. no one provider, even/especially Microsoft should have alll a user's identity info). While the SSO aspect of .NET Passport was apparently very successful amongst other Microsoft sites (e.g. MSN), other aspects (like the wallet) were not taken advantage of.
Like a giraffe's neck being lengthened through the exercises of its ancestors reaching for sweet acacia leaves, or like a mole rat losing its vision through successive generations of living in the dark, Microsoft is positioning .NET Passport's offspring as benefiting from the experiences of its ancestor. We have learned! What wasn't used is gone! We are now in context!
Lamarck would love it. Darwin not so much.
Strictly speaking, this would appear to be an example of the Baldwin Effect rather than a true Lamarckism.
Lamarck postulated that animals acquire characteristics through their experiences and, importantly, these characteristics can be passed onto their offspring. The archetypical example is that the giraffe developed such a long neck through successive generations of animals extending their necks to get to the tender leaves on the higher branches of trees. Each generation saw the necks get a little bit longer as the animals continued to stretch out. The efforts of one generation were manifested in the next, the offspring benefited from what their parents had attempted.
Lamerck's theory - this inheritance of acquired characteristics is now widely refuted (including through experiments that had the tails of mice cut off for generations and yet they continued to be present on babies). Darwin's theory of natural selection is now accepted as the true driver of evolution.
.NET Passport is Microsoft's now much derided web-based identity management scheme that never really reached the potential that Microsoft seemed to imagine for it. .NET Passport spent its life in an environment of mistrust (e.g. why would I share my credit card with Microsoft) and privacy concerns (e.g. no one provider, even/especially Microsoft should have alll a user's identity info). While the SSO aspect of .NET Passport was apparently very successful amongst other Microsoft sites (e.g. MSN), other aspects (like the wallet) were not taken advantage of.
Like a giraffe's neck being lengthened through the exercises of its ancestors reaching for sweet acacia leaves, or like a mole rat losing its vision through successive generations of living in the dark, Microsoft is positioning .NET Passport's offspring as benefiting from the experiences of its ancestor. We have learned! What wasn't used is gone! We are now in context!
Lamarck would love it. Darwin not so much.
Strictly speaking, this would appear to be an example of the Baldwin Effect rather than a true Lamarckism.
Friday, May 20, 2005
Meta-Interoperability
Sun and Microsoft's recently announced Web Single Sign On Interoperability Profile defines both how the Web Single Sign On Metadata Exchange Protocol can be used by providers to determine what SSO protocol suites another uses (e.g. Liberty ID-FF 1.2 or something else) and some slim profiles of those other protocol suites.
The profile specifies that, to be compliant, you MUST only use the Liberty ID-FF Browser POST Profile - the other profiles (e.g. artifact based) are excluded. WS-Federation is similarly constrained (although WS-Federation doesn't have anything comparable to an artifactt so there is no need to exclude it).
Although not stated in the document, the presumed goal of constraining both ID-FF and WS-Federation in this manner is to align the two of them into the same message exchange pattern (MEP), specifically one in which service provider and identity provider communicate with each other 'through' the browser using HTML form posts. I guess the thought is that by converging on this MEP, either provider can easily swap in or out either protocol, differing as they are only by XML syntax.
This seems a new twist on enabling interopability through constraint as practised by WS-I.org (perhaps why this work was not done within that organization?). In WS-I, groups of complementary standards are constrained as a group so that the end result is a consistent and interoperable combination.
The 'interoperability profile' of Sun and Microsoft seems a different beast. In it, two equivalent SSO suites (varying along the standards body ratification scale) are individually constrained to bring each into alignment with a common pattern. This is a different type of interopability, in no sense could it be said that ID-FF and WS-Federation 'work together' as do SOAP and WSDL in the WS-I Basic profile. Rather, by aligning with this common pattern, what is being enabled is the ability for providers to easily switch (even at run time) between both suites.
As 'meta' seems to be enjoying a resurgence in popularity lately, let's call this type of interoperability 'meta-interoperability'.
Maybe the 'interoperability profile' will even eventually be submitted to MWS-I.org?
The profile specifies that, to be compliant, you MUST only use the Liberty ID-FF Browser POST Profile - the other profiles (e.g. artifact based) are excluded. WS-Federation is similarly constrained (although WS-Federation doesn't have anything comparable to an artifactt so there is no need to exclude it).
Although not stated in the document, the presumed goal of constraining both ID-FF and WS-Federation in this manner is to align the two of them into the same message exchange pattern (MEP), specifically one in which service provider and identity provider communicate with each other 'through' the browser using HTML form posts. I guess the thought is that by converging on this MEP, either provider can easily swap in or out either protocol, differing as they are only by XML syntax.
This seems a new twist on enabling interopability through constraint as practised by WS-I.org (perhaps why this work was not done within that organization?). In WS-I, groups of complementary standards are constrained as a group so that the end result is a consistent and interoperable combination.
The 'interoperability profile' of Sun and Microsoft seems a different beast. In it, two equivalent SSO suites (varying along the standards body ratification scale) are individually constrained to bring each into alignment with a common pattern. This is a different type of interopability, in no sense could it be said that ID-FF and WS-Federation 'work together' as do SOAP and WSDL in the WS-I Basic profile. Rather, by aligning with this common pattern, what is being enabled is the ability for providers to easily switch (even at run time) between both suites.
As 'meta' seems to be enjoying a resurgence in popularity lately, let's call this type of interoperability 'meta-interoperability'.
Maybe the 'interoperability profile' will even eventually be submitted to MWS-I.org?
Thursday, May 19, 2005
WS-KindofInteresting
Sun and Microsoft recently announced some fruits of their relationship in the identity management and web services space, the wonderfully named WSSOMEP (I think they missed out on the chance to call it SOME (Sign On Metadata Exchange))
WSSOMEP defines how WS-MetadataExchange can be used to determine which Single Sign-On protocol suites (SAML 1.1, ID-FF 1.2, SAML 2.0, WS-Federation, etc) your partner is capable of supporting so that the two of you can actually do something interesting (like enabling SSO for your customers, employees, etc).
WS-MetadataExchange defines a SOAP-based request/response protocol. Fundamentally, one provider says to the other 'tell me what you can do'. If the returned list includes something that the asking provider can also 'so', then we have an intersection of capabilities and we're off to the races. If no intersection, no way forward.
Once you work out the intersection, obviously you don't forget it the next time you want to do SSO so this mechanism is a one time deal between provider pairs (maybe you'd ask for an update occasionally to make sure you aren't falling behind the technology curve)
So this is one way to address the 'what can the other guy do' issue. There are others. Here is my list:
ask the other guy (WSSOMEP model)
look it up (metadata file at well-known location)
ask somebody else (UDDI)
trial and error, e.g. use one of the suites and, if it works, fine. If not, glean something from the error message
What others are there?
For Liberty's ID-Web Services Framework, the Web Services Consumer (WSC) is able to discover versioning support of its eventual partner Web Services Provider (WSP) by interacting with the Discovery Service. The knowledge it gains about the capabilities of the WSP is implicit however, it never explicitly asks the question 'what can the other guy do' but rather 'give me everything I need in order to talk to the other guy'. The 'everything I need' includes the required versioning info.
WSSOMEP defines how WS-MetadataExchange can be used to determine which Single Sign-On protocol suites (SAML 1.1, ID-FF 1.2, SAML 2.0, WS-Federation, etc) your partner is capable of supporting so that the two of you can actually do something interesting (like enabling SSO for your customers, employees, etc).
WS-MetadataExchange defines a SOAP-based request/response protocol. Fundamentally, one provider says to the other 'tell me what you can do'. If the returned list includes something that the asking provider can also 'so', then we have an intersection of capabilities and we're off to the races. If no intersection, no way forward.
Once you work out the intersection, obviously you don't forget it the next time you want to do SSO so this mechanism is a one time deal between provider pairs (maybe you'd ask for an update occasionally to make sure you aren't falling behind the technology curve)
So this is one way to address the 'what can the other guy do' issue. There are others. Here is my list:
What others are there?
For Liberty's ID-Web Services Framework, the Web Services Consumer (WSC) is able to discover versioning support of its eventual partner Web Services Provider (WSP) by interacting with the Discovery Service. The knowledge it gains about the capabilities of the WSP is implicit however, it never explicitly asks the question 'what can the other guy do' but rather 'give me everything I need in order to talk to the other guy'. The 'everything I need' includes the required versioning info.
Subscribe to:
Comments (Atom)