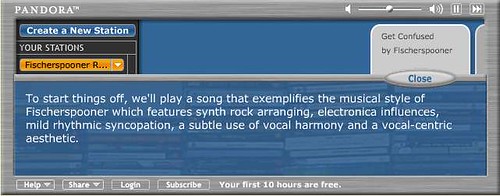
Pandora asks you to provide the name of an artist or song as a starting point. Then, based on its prior analysis of the song or artist, it recommends 'similar' songs that meet the search criteria. Amazingly, the analysis of each song is perfromed by humans
Together our team of thirty musician-analysts have been listening to music, one song at a time, studying and collecting literally hundreds of musical details on every song. It takes 20-30 minutes per song to capture all of the little details that give each recording its magical sound - melody, harmony, instrumentation, rhythm, vocals, lyrics ... and more - close to 400 attributes!
The Pandora player streams these relevant songs and allows you to customize with your likes/dislikes. So, you can modify the default recommendation playlist but, out of the box, the default is not targetted at particular users.
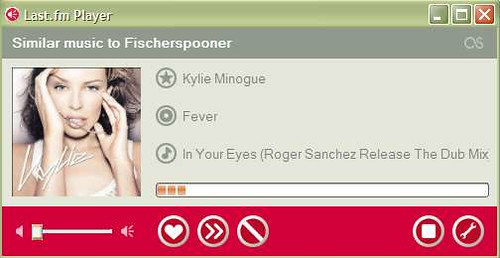
Last.fm bases its recommendations as to what you might enjoy hearing based not on any intrinsic attributes of a song or artist, but rather on the proximity of songs to each other in a social space. For instance, if two users share a taste in a particular artist (these tastes tracked by a music plug-in for players that pushes played songs to the Last.fm database and presumably weighted by the number of plays) then the sytem assumes that one user would enjoy listening to other songs in the other user's playlist. What I hear is based partly on what those who are close to me in this "taste space" like to listen to. A refinement of the Last.fm model would allow me to assing greater weight to particular users (Last.fm allows me to identify 'friends' but it's not clear whether they are factored into the recommendation algorythm).
Early comparisons of the success rate, (e.g. delivering me a song that I do indeed enjoy) seems to favour Pandora, perhaps not surprising given the heavy-lifting that has gone into creation of the database. Last.fm's recommendations will likely improve as more and more users join-up so that the current occasional perversions (see below) would be swamped out by numbers.
No comments:
Post a Comment